| fungi | assuming he's talking about the 110bps kind you set the telephone handset onto | 00:00 |
|---|---|---|
| clarkb | I never had one myself but knew immediately what it was when I first saw a picture. All of a sudden those modem noises made so much sense to me :) | 00:00 |
| paladox | heh | 00:00 |
| fungi | https://en.wikipedia.org/wiki/Acoustic_coupler | 00:01 |
| clarkb | we were always quite a few years behind on technology growing up so by the time the internet made it to the island via satellite connection 56kbps modems were the thing | 00:01 |
| paladox | clarkb fungi https://www.gadgetspeak.com/aimg/565737-bt-home-hub-2-n.jpg | 00:01 |
| fungi | yeah, that looks a good deal more fancy than what i was thinking of | 00:02 |
| paladox | clarkb super fast broadband only hit my area in 2012. | 00:02 |
| fungi | i mean, it has buttons | 00:02 |
| *** mattw4 has quit IRC | 00:02 | |
| fungi | the phone i used my coupler with still used a rotary dial | 00:02 |
| paladox | I remember that because they upgraded the green boxes outside i think. | 00:03 |
| clarkb | palaodx: current speeds and rates back home https://www.fsmtc.fm/internet/adsl | 00:03 |
| fungi | then again, we didn't even get dtmf service where i lived until i was in my teens, so pushbutton phones were fairly irrelevant (though there were some that had a switch to go into "pulse dialing" mode) | 00:03 |
| paladox | :O | 00:03 |
| clarkb | looks like *Mbps for $220/month | 00:04 |
| paladox | adsl is slow! | 00:04 |
| clarkb | er 8Mbps | 00:04 |
| paladox | it's expensive in the US | 00:04 |
| clarkb | oh thats not the US | 00:04 |
| clarkb | in the US I pay $85/month for 100/100 Mbps symmetric connectivity | 00:04 |
| paladox | oh | 00:04 |
| clarkb | I think I can actually get that up to 200/200 now for maybe the same price | 00:04 |
| clarkb | paladox: I grew up on an island in the middle of the pacific | 00:05 |
| paladox | oh | 00:05 |
| fungi | clarkb: it's probably sad then that my parents live in the continental usa and pay similar rates for similar speeds of dsl connection as on that chart | 00:05 |
| clarkb | fungi: ouch | 00:05 |
| fungi | they're lucky the phone company even started offering dsl at all. the only broadband option before that was hughes/directv satellite | 00:05 |
| paladox | In the UK, ofcom regulate the ISP's, which is awesome! Because then things doin't become too expensive. | 00:05 |
| fungi | they've had dsl available for ~5 years now | 00:06 |
| paladox | dsl only came to you 5 years ago? | 00:06 |
| fungi | to where i grew up and my parents still live, i've moved out decades ago | 00:06 |
| paladox | heh | 00:07 |
| fungi | the service where i live now is still crap but it's orders of magnitude faster | 00:07 |
| paladox | we got rid of dsl the year bt brough infinity to my area! | 00:07 |
| paladox | *brought | 00:07 |
| clarkb | I've got fiber to my home but the prices for gigabit are silly so I don't pay for it | 00:08 |
| fungi | rural usa is woefully underserved by broadband providers | 00:08 |
| paladox | They've only just started rolling out gigabit here! | 00:08 |
| clarkb | my ISP is actually getting acquired and I'm hoping that gigabit prices come down as a result | 00:08 |
| paladox | BT offer gift cards if your new to them. | 00:09 |
| fungi | fastest speed of any broadband provider on the island here is 100mbps (charter/spectrum cable), which i consider not bad, but then again my standards are not high and my needs are not either | 00:09 |
| paladox | fungi that's faster by 20-30mb then what i have :) | 00:09 |
| paladox | 80mbps | 00:09 |
| paladox | though they cannot market it as 80mbps anymore. | 00:10 |
| fungi | i mean, i probably don't actually *get* 100mbps, i've never really tested it, and it seems to get overwhelmed during tourist season | 00:10 |
| fungi | plus they like to just turn it off at random during the week in the off-season to do maintenance, because they assume the island is basically vacant and nobody will notice | 00:11 |
| paladox | heh | 00:11 |
| paladox | bt offer a speed gurentee now. | 00:12 |
| paladox | on certain plans. | 00:12 |
| fungi | guarantees are virtually nonexistent in the usa. for business use you can sometimes get an sla, but what that generally means is if you notice they're not meeting the agreement then you can ask for a pro-rated redund of lost service | 00:13 |
| fungi | and an sla on residential service is basically unheard of | 00:14 |
| paladox | heh | 00:14 |
| paladox | https://www.bt.com/broadband/deals/ | 00:14 |
| fungi | i should clarify, consumer protection is virtually nonexistent in the usa, and companies can usually get away with lying to you through their teeth with no real ramifications | 00:15 |
| paladox | oh | 00:16 |
| paladox | :( | 00:16 |
| fungi | 99% of customers won't realize they're being lied to, and the remaining 1% will spend more time and money fighting to get a refund than it's ultimately worth | 00:16 |
| paladox | heh | 00:17 |
| fungi | result: profit! | 00:17 |
| * fungi is a bit of a cynic | 00:18 | |
| paladox | fungi we have an advertising regulator too! | 00:19 |
| fungi | wow | 00:19 |
| paladox | fungi and consumers can complain :) | 00:20 |
| fungi | i mean, we do have places to complain, but it's like the proverbial "complaints" sign on the paper shredder | 00:21 |
| paladox | fungi https://www.asa.org.uk | 00:21 |
| *** pkopec has joined #openstack-infra | 00:21 | |
| paladox | We have ofgem (regulates engergy companys), ofstead (regulates scools/furthur education), asa, ofcom. | 00:22 |
| fungi | we have those things too, but generally the industries being regulated buy enough politicians to get their cronies appointed to run the regulatory bodies | 00:23 |
| paladox | heh | 00:24 |
| paladox | it's all independant here | 00:24 |
| * paladox expecially likes ofcom! | 00:25 | |
| donnyd | ok I added some static rageroutes | 00:25 |
| paladox | it forced my mobile network to offer me unlimited tethering | 00:25 |
| paladox | as i'm on a unlimited data plan | 00:25 |
| fungi | paladox: score! | 00:25 |
| donnyd | should keep the mirror traffic from going all the way up and down | 00:25 |
| fungi | donnyd: anything in particular we should keep an eye on? do we need to add any routes on the mirror itself? | 00:26 |
| fungi | or is this all handled by the respective gateways still? | 00:26 |
| donnyd | fungi: they should be handled in the openstack router, so nah | 00:26 |
| fungi | awesome. thanks! | 00:26 |
| donnyd | I just dropped a static route in the router of each project | 00:27 |
| fungi | will keep an eye out for any obvious connectivity issues between nodes and the mirror | 00:27 |
| donnyd | https://www.irccloud.com/pastebin/bSBPNA4q/ | 00:27 |
| *** armax has quit IRC | 00:28 | |
| fungi | looks good to me | 00:28 |
| donnyd | so I still have a bit of work to do to solve non-mirror related traffic inbound and outbound | 00:28 |
| donnyd | however the large majority of failures we were seeing were related to talking to the mirror | 00:29 |
| donnyd | short of ipv6 just not working correctly at all, i can't get a much more direct path to the mirror and something else is up | 00:29 |
| fungi | fingers crossed, but this seems likely to help | 00:30 |
| donnyd | yea I can imagine that taking out the extra hop will make things work a bit better... next on the list is to solve once and for all the retransmission issue | 00:31 |
| donnyd | I have some ideas, but I really need to test this out and see where why they are occuring | 00:31 |
| donnyd | Hopefully I have an answer by tomorrow | 00:32 |
| openstackgerrit | Ian Wienand proposed opendev/glean master: Update testing to opensuse 15 https://review.opendev.org/679512 | 00:32 |
| donnyd | just for giggles, do you think you could fire up iperf3 in the mirror | 00:33 |
| fungi | sure, just a sec while i get my notes | 00:34 |
| donnyd | iperf3 -s | 00:36 |
| fungi | well, more importantly making sure i open the right ports in iptables | 00:36 |
| *** xenos76 has quit IRC | 00:36 | |
| donnyd | should be tcp/5201 if I am not mistaken | 00:37 |
| fungi | 5201/tcp | 00:37 |
| fungi | looks like | 00:37 |
| fungi | yeah | 00:37 |
| *** rosmaita has quit IRC | 00:39 | |
| donnyd | thanks fungi | 00:40 |
| fungi | Server listening on 5201 | 00:42 |
| fungi | give it a whirl | 00:42 |
| fungi | i've opened that port in iptables for both v6 and v6 traffic | 00:42 |
| fungi | er, both v4 and v5 | 00:43 |
| fungi | gah | 00:43 |
| * fungi stops trying to type | 00:43 | |
| *** Garyx_ has quit IRC | 00:49 | |
| *** rosmaita has joined #openstack-infra | 00:52 | |
| clarkb | cmurphy: https://storage.gra1.cloud.ovh.net/v1/AUTH_dcaab5e32b234d56b626f72581e3644c/zuul_opendev_logs_d32/681691/1/gate/cross-keystone-py35/d32391c/ that failed with a timeout do we need to bump the requirements side too? | 00:52 |
| cmurphy | clarkb: yeah we can but since requirements is frozen i figured it wasn't as high a priority | 00:53 |
| *** gyee has quit IRC | 00:53 | |
| donnyd | fungi: ok it looks pretty good to me | 00:56 |
| fungi | still using it or should i button it back up now? | 00:56 |
| donnyd | its def not hitting the edge and performance is expected | 00:56 |
| donnyd | you can take it back down | 00:57 |
| *** pkopec has quit IRC | 00:57 | |
| fungi | thanks again, on it | 00:57 |
| donnyd | thanks... i just wanted to validate that flows will run around the 10G mark | 00:57 |
| donnyd | https://www.irccloud.com/pastebin/ho4EZJrb/ | 00:57 |
| donnyd | not too bad for a single thread | 00:58 |
| donnyd | I dont have dpdk running or any network acclerators, so that is pretty good | 00:58 |
| donnyd | I just need to develop a load test to make sure that retransmissions aren't crazy... some are normal, but millions are not | 01:00 |
| fungi | okay, iperf3 stopped and uninstalled, temporary iptables rules deleted, all back to normal | 01:01 |
| *** markvoelker has joined #openstack-infra | 01:01 | |
| *** calbers has quit IRC | 01:02 | |
| *** Garyx has joined #openstack-infra | 01:03 | |
| *** markvoelker has quit IRC | 01:05 | |
| donnyd | fungi: ok it looks to me like setting the mtu on my tunnel interface has significantly lowered the retransmissions | 01:09 |
| openstackgerrit | Donny Davis proposed openstack/project-config master: Direct Mirror route + Path MTU fixed Reenable FN https://review.opendev.org/681951 | 01:11 |
| fungi | good deal | 01:13 |
| donnyd | in ntop you can watch a connection and it seemed like every other packet was a retrans... now I see none | 01:15 |
| clarkb | donnyd: that is after swapping in the neutron router for your edge router? | 01:15 |
| donnyd | So for ipv4 there it is now using an openstack router with a direct public connection | 01:17 |
| donnyd | For ipv6 traffic destined for the mirror there is a static route in the v6 Openstack router that points directly to the mirror | 01:17 |
| donnyd | For ipv6 traffic destined for not the mirror it still hits the edge, but this time with a proper MTU value | 01:17 |
| donnyd | in v6 land, the connection goes as follows - test node -> Zuul tenant Openstack Router -> Mirror Tenant Openstack Router -> Mirror | 01:18 |
| donnyd | It used to go - test node -> Zuul tenant Openstack Router -> Edge Router -> Mirror Tenant Openstack Router -> Mirror | 01:19 |
| donnyd | So now the connection never leaves the network node for mirror bound traffic | 01:19 |
| donnyd | So to fix v4 connection issues the Openstack router will relieve the pressure on the edge router NAT table, because before it was getting 100% of the load.. Now it just services non zuul tenant traffic | 01:21 |
| donnyd | I am hoping we have a winner winner chicken dinner | 01:22 |
| clarkb | makes sense | 01:22 |
| *** mriedem_afk has quit IRC | 01:23 | |
| donnyd | In all honesty it really makes no sense.. I have had the exact same edge router config doing 100X more... but it was mostly voip traffic, so maybe not a noisy | 01:23 |
| fungi | that's usually longer established sessions | 01:24 |
| fungi | so less churn on the nat table | 01:24 |
| donnyd | yea, and I am thinking exactly that is the issue on the v4 side | 01:24 |
| donnyd | its not expiring fast enough to keep up | 01:25 |
| fungi | it's usually rapid nat session turnover which burns you because of the cooldown before a port can be reallocated for another session | 01:25 |
| donnyd | I can fix that for CI purposes... but I worry it will break lots of other things around here... and I would worry about effecting the other services and the way they currently function | 01:25 |
| fungi | makes sense | 01:26 |
| donnyd | I can turn it down to kill the state in milli seconds.. but then it also may drop non busy connections too | 01:26 |
| donnyd | so I am thinking this change will solve both the v4 issues we have seen and the v6 issues | 01:27 |
| donnyd | Won't know for sure till a full load is back on... but even with a light load before it was 100% clear something was wrong | 01:27 |
| fungi | i recall one customer years back who operated a mobile browsing gateway service for cellphone providers and had to do a ton of nat to map between disparate and conflicting private phone networks. the connection churn was so bad we needed almost 10x as many ports in the nat pool as their peak for concurrent sessions | 01:28 |
| donnyd | In the last 30 or so minutes there have been about 15 retransmissions | 01:28 |
| clarkb | fungi: this is why they all run ipv6 now | 01:28 |
| donnyd | before it would have been 5-8K in the same time period | 01:28 |
| fungi | yup | 01:28 |
| clarkb | the one place in this country you can get an ipv6 address is your cell phone network | 01:28 |
| fungi | clarkb: except if you want to tether to it, and then you end up with an ipv4 network masquerading behind your v6-routerphone | 01:30 |
| donnyd | it really makes a lot of sense for cell phones.. they are so transient and v4 space is so limited | 01:30 |
| fungi | so silly | 01:30 |
| fungi | they could easily route a /64 behind every cellphone in the world and not even make a dent in v6 address consumption | 01:31 |
| donnyd | So here is a good example of the fix | 01:31 |
| donnyd | https://usercontent.irccloud-cdn.com/file/kb4MEjSF/image.png | 01:31 |
| *** dave-mccowan has quit IRC | 01:31 | |
| donnyd | This is an inbound ssh connection and before the retransmit # would have been in the 500-1k mark by now | 01:32 |
| fungi | yeesh | 01:32 |
| donnyd | Also I hope all of this data is helpful to someone down the road... or at least for our own education | 01:33 |
| fungi | it's been very enlightening for me so far | 01:33 |
| donnyd | they could give everyone their own permanent /50 and still not even touch v6 | 01:33 |
| fungi | if you every get an opportunity to summarize your work on this in an article or a conference talk, i'm certain it would be useful too | 01:34 |
| fungi | well, it would probably be a /56 or a /48... easier to carve on octet boundaries for reverse dns zone delegation purposes | 01:35 |
| donnyd | Yea it would be good to write it all up once it actually works really well. I don't have big money gear doing any of this... anyone could do the same thing | 01:35 |
| donnyd | yea that is true | 01:35 |
| fungi | mtreinish had a great talk a few years back about his "closet cloud" and this could make an interesting sequel | 01:36 |
| donnyd | It has taken quite a lot of "test and tune" to get this thing to perform close to what the big guys like vexxhost and ovh can do | 01:37 |
| fungi | though he didn't have nearly as many hosts | 01:37 |
| fungi | and was doing it on a very shoestring budget | 01:37 |
| donnyd | I have 8 compute nodes / one controller / two swift / one cinder | 01:38 |
| donnyd | although I am thinking with as little space as the swift service is taking, I may run it on the openstack infra so I can take advantage of the nvme drives | 01:39 |
| fungi | yeah, i think he said his was 4 compute nodes, but probably also lower-end servers (it was also longer ago) | 01:39 |
| *** JorgeFranco has joined #openstack-infra | 01:39 | |
| fungi | i think they were used dell 1u rackmounts he got for a song on ebay | 01:40 |
| donnyd | yea that's my play too | 01:40 |
| donnyd | I wear people down on ebay and get them for nothing | 01:41 |
| donnyd | each of the compute nodes 4X cpus 128G ram I got for 200 bucks each | 01:41 |
| fungi | yeah, that's a remarkable deal | 01:42 |
| donnyd | the nvme stuff was a little on the pricey side.. but less than most people pay for a gaming rig | 01:42 |
| donnyd | 24T of nvme is what I got in the compute nodes... any guesses how much I paid? | 01:42 |
| fungi | i don't really know the going rate, i think i paid a few hundred last year for 2tb | 01:43 |
| donnyd | just for proof its actually fixed | 01:43 |
| donnyd | https://usercontent.irccloud-cdn.com/file/Ix9FqH24/image.png | 01:43 |
| donnyd | 1 more retransmission | 01:43 |
| donnyd | but that is acceptable | 01:43 |
| fungi | yeah, might as well be 0 compared to before | 01:44 |
| donnyd | in the time I had it up there were a total of 43M | 01:44 |
| donnyd | it was only up for a short while... so yea I would say its in much better shape | 01:45 |
| donnyd | 1800 bucks for the nvme drives | 01:45 |
| donnyd | or $1.3 per GB | 01:45 |
| donnyd | not too bad | 01:46 |
| *** whoami-rajat has quit IRC | 01:47 | |
| openstackgerrit | Merged openstack/project-config master: Direct Mirror route + Path MTU fixed Reenable FN https://review.opendev.org/681951 | 01:48 |
| fungi | not bad? that's crazy inexpensive | 01:48 |
| *** dolpher has quit IRC | 01:49 | |
| donnyd | I just keep making offers until they take it... I usually get told no... but every now and again someone says eff it | 01:49 |
| donnyd | My favorite thing to do is when i make an offer for say 100 dollars on something and they come back with 120.. I send another offer for 90 | 01:49 |
| donnyd | LOL | 01:49 |
| fungi | genius | 01:50 |
| fungi | you clearly paid attention to the haggling scene in life of brian | 01:50 |
| donnyd | I have never seen it.. but now I am going to | 01:51 |
| fungi | it's a brief scene, but iconic | 01:51 |
| fungi | brian's in a hurry (on the run), doesn't want to haggle to buy a disguise at a market stall, and the purveyor proceeds to lay into him with a lesson on how to haggle | 01:52 |
| fungi | one of eric idles more memorable performances on the big screen | 01:54 |
| *** tkajinam has quit IRC | 01:54 | |
| donnyd | I am going to have to check it out | 01:55 |
| donnyd | I am going to stick around till some jobs are scheduled to make sure there are no/minor issues... | 01:56 |
| fungi | thanks, i'm here to help with any reverts | 01:56 |
| fungi | should be up for a few hours still | 01:56 |
| donnyd | I need to turn on skydive so people can introspect the traffic on FN | 01:57 |
| donnyd | ever seen it? | 01:58 |
| fungi | not sure i have context. a network visualization app? | 02:01 |
| fungi | aha, http://skydive.network/ | 02:02 |
| fungi | looks vaguely familiar | 02:02 |
| fungi | that might have made an appearance in a conference talk i saw, hard to remember. does certainly look neat | 02:03 |
| *** apetrich has quit IRC | 02:10 | |
| *** tkajinam has joined #openstack-infra | 02:11 | |
| donnyd | It lets you get into the SDN of Openstack and see what is going on | 02:22 |
| donnyd | you can even use the traffic generator to make sure a connection that should work does | 02:23 |
| *** markvoelker has joined #openstack-infra | 02:26 | |
| *** hongbin has joined #openstack-infra | 02:32 | |
| *** roman_g has quit IRC | 02:34 | |
| *** tkajinam has quit IRC | 02:36 | |
| *** markvoelker has quit IRC | 02:36 | |
| openstackgerrit | Merged opendev/glean master: Update testing to opensuse 15 https://review.opendev.org/679512 | 02:36 |
| *** markvoelker has joined #openstack-infra | 02:38 | |
| *** markvoelker has quit IRC | 02:43 | |
| *** tkajinam has joined #openstack-infra | 02:56 | |
| *** dklyle has quit IRC | 02:57 | |
| *** dklyle has joined #openstack-infra | 03:00 | |
| donnyd | I have just about got it all up and running if your curious to take a look | 03:01 |
| donnyd | about 5 more minutes and i should be done | 03:01 |
| fungi | sure, still around | 03:02 |
| *** rf0lc0 has quit IRC | 03:05 | |
| *** bobh has joined #openstack-infra | 03:08 | |
| donnyd | https://openstack.fortnebula.com:8082/topology | 03:14 |
| donnyd | lmk if you can see this | 03:14 |
| *** ramishra has joined #openstack-infra | 03:16 | |
| fungi | checking | 03:16 |
| fungi | yep! it loads | 03:17 |
| *** njohnston has quit IRC | 03:17 | |
| fungi | and i can reorient the topology view/gravity and stuff just fine | 03:18 |
| donnyd | so i will probably turn the auth back on in the near future.. but this could be real handy for T/S the network issues | 03:19 |
| donnyd | and all the data is saved in elastic | 03:19 |
| fungi | (firefox in debian/unstable with no fancy plugins besides some privacy extensions) | 03:19 |
| fungi | yeag, it looks like stuff like the generator isn't locked down, so you probably don't want it left open | 03:20 |
| fungi | also careful not to expose your elasticsearch api, like, ever | 03:20 |
| donnyd | yea, elastic is no good for the interwebs | 03:21 |
| donnyd | I'm sure there are bots constantly scanning for it | 03:22 |
| fungi | we have one backending our wiki search which accidentally got exposed once during an in-place distro upgrade where iptables-persistent and puppet decided to fight it out over what files were symlinks so we ended up with a self-referential pair of symlinks for firewall rules... elacticsearch was compromised in minutes | 03:23 |
| *** bobh has quit IRC | 03:25 | |
| donnyd | woops | 03:26 |
| fungi | and the skydive tab i had open just threw up a sign in widget! wow that's reactive | 03:26 |
| donnyd | So lets say I needed to find some traffic.. I could just use the capture interface to find what I am looking for and get some metrics or something fancy like that | 03:27 |
| donnyd | So go click on the openstack bubble and then br-int | 03:30 |
| donnyd | If you want to see whats happening, you can click create capture, and then put to cursor in interface 1 and then click br-int again | 03:31 |
| donnyd | and it will start caputring traffic on that bridgr | 03:32 |
| donnyd | and then head over to the flows tab and you can see traffic moving | 03:32 |
| donnyd | and of course you can use a BPF filter to see something more specific | 03:33 |
| *** hongbin has quit IRC | 03:34 | |
| donnyd | so its been a while and FN is still sitting at 10 nodes... should be 20 | 03:34 |
| *** factor has quit IRC | 03:35 | |
| fungi | looks like it's still max-servers: 0 in the config on disk for nl02 | 03:36 |
| fungi | i'll see if we're having trouble puppeting it | 03:36 |
| fungi | Sep 13 01:47:36 nl02 puppet-user[20819]: Applied catalog in 6.05 seconds | 03:37 |
| fungi | so it's been nearly 2 hours since the last pulse completed | 03:37 |
| fungi | something has caused our configuration management updates to take in the neighborhood of 100+ minutes recently | 03:38 |
| fungi | that's no good | 03:38 |
| fungi | will see if i can identify the cause of the slowdown | 03:39 |
| fungi | it was closer to 45 minutes up until the last few pulses | 03:40 |
| fungi | tons of defunct ansible-playbook processes with a start time of 02:18z | 03:48 |
| fungi | looks like the only active connection is to storyboard-dev | 03:52 |
| fungi | and i'm timing out trying to ssh into it | 03:52 |
| *** JorgeFranco has quit IRC | 03:54 | |
| donnyd | well that is not good | 03:54 |
| fungi | yeah, pulling up console access for the instance | 03:54 |
| fungi | hung kernel tasks spamming the virtual console | 03:56 |
| fungi | going to reboot it | 03:57 |
| *** rh-jelabarre has quit IRC | 03:58 | |
| fungi | and now i can ssh into it again | 03:58 |
| fungi | killed the stuck ansible ssh process to that server and it's proceeding to configure servers again | 03:59 |
| fungi | #status log hard-rebooted storyboard-dev due to hung kernel tasks rendering server unresponsive, killed stuck ansible connection to it from bridge to get configuration management to resume a timely cadence | 04:00 |
| openstackstatus | fungi: finished logging | 04:00 |
| donnyd | So I am working on that swift dashboard widget so we can see trends | 04:01 |
| donnyd | i have something up there.. but no idea if that is what we are looking for | 04:01 |
| fungi | neat. i think once i see nl02 pick up the fn max-servers change i'm knocking off for the night | 04:01 |
| donnyd | yea me too, i need to get some zzs | 04:02 |
| donnyd | thanks for the help fungi :) | 04:02 |
| fungi | my pleasure. and thanks for yours! | 04:02 |
| donnyd | clarkb: https://grafana.fortnebula.com/d/9MMqh8HWk/openstack-utilization?from=now%2FM&to=now&fullscreen&panelId=26 | 04:04 |
| *** ykarel|away has joined #openstack-infra | 04:06 | |
| donnyd | It's pretty ugly.. but I am not entirely sure what you are looking for | 04:07 |
| * donnyd pulls ripcord and jumps out the plane | 04:11 | |
| donnyd | I am headed out fungi | 04:11 |
| *** eharney has joined #openstack-infra | 04:11 | |
| *** markvoelker has joined #openstack-infra | 04:16 | |
| *** markvoelker has quit IRC | 04:21 | |
| *** eharney has quit IRC | 04:27 | |
| *** kjackal has joined #openstack-infra | 04:31 | |
| *** exsdev has quit IRC | 04:41 | |
| *** exsdev has joined #openstack-infra | 04:43 | |
| *** ykarel|away has quit IRC | 04:43 | |
| *** pcaruana has joined #openstack-infra | 05:02 | |
| *** udesale has joined #openstack-infra | 05:08 | |
| *** ykarel|away has joined #openstack-infra | 05:13 | |
| *** jtomasek has joined #openstack-infra | 05:16 | |
| *** diablo_rojo has quit IRC | 05:30 | |
| *** tkajinam has quit IRC | 05:54 | |
| *** tkajinam has joined #openstack-infra | 06:03 | |
| *** xek has joined #openstack-infra | 06:03 | |
| *** ykarel|away is now known as ykarel | 06:03 | |
| *** rpittau|afk is now known as rpittau | 06:08 | |
| *** xek has quit IRC | 06:12 | |
| *** xek has joined #openstack-infra | 06:13 | |
| *** ralonsoh has joined #openstack-infra | 06:14 | |
| *** tkajinam_ has joined #openstack-infra | 06:19 | |
| *** tkajinam has quit IRC | 06:22 | |
| *** kjackal has quit IRC | 06:24 | |
| *** slaweq has joined #openstack-infra | 06:51 | |
| *** lpetrut has joined #openstack-infra | 06:54 | |
| *** diga has quit IRC | 06:55 | |
| *** trident has quit IRC | 06:55 | |
| *** xek has quit IRC | 06:56 | |
| *** pkopec has joined #openstack-infra | 06:56 | |
| *** pgaxatte has joined #openstack-infra | 06:57 | |
| *** kjackal has joined #openstack-infra | 07:00 | |
| *** whoami-rajat has joined #openstack-infra | 07:02 | |
| *** udesale has quit IRC | 07:04 | |
| *** lajoskatona has joined #openstack-infra | 07:06 | |
| *** jbadiapa has joined #openstack-infra | 07:06 | |
| *** trident has joined #openstack-infra | 07:07 | |
| *** Florian has joined #openstack-infra | 07:10 | |
| *** kaiokmo has quit IRC | 07:12 | |
| *** tosky has joined #openstack-infra | 07:12 | |
| *** tesseract has joined #openstack-infra | 07:15 | |
| lajoskatona | frickler: Hi, a question: Is there a way to give more that 8Gb memory to ODL tempest executions? By dstat it seems that ODL (java.....) consumes all memory, and I suppose vm boot and other things are starving, this is why we have ugly timeouts. | 07:15 |
| openstackgerrit | Merged opendev/system-config master: fedora mirror update : add sleep https://review.opendev.org/681367 | 07:15 |
| evrardjp | corvus: I see you your name in system-config/kubernetes/percona-xtradb-cluster. I wanted to hear about the stability of that helm chart, and if you tried other things :) | 07:17 |
| *** tosky_ has joined #openstack-infra | 07:18 | |
| *** ralonsoh has quit IRC | 07:19 | |
| *** shachar has quit IRC | 07:20 | |
| *** ralonsoh has joined #openstack-infra | 07:21 | |
| *** tosky has quit IRC | 07:21 | |
| *** ramishra has quit IRC | 07:26 | |
| *** ramishra has joined #openstack-infra | 07:28 | |
| *** jaosorior has joined #openstack-infra | 07:35 | |
| *** prometheanfire has quit IRC | 07:36 | |
| *** gfidente has joined #openstack-infra | 07:37 | |
| *** prometheanfire has joined #openstack-infra | 07:38 | |
| *** tosky_ is now known as tosky | 07:38 | |
| *** jpena|off is now known as jpena | 07:40 | |
| AJaeger | evrardjp: good morning, do you need https://review.opendev.org/673019 before train branches are created? | 07:44 |
| *** kaiokmo has joined #openstack-infra | 07:45 | |
| openstackgerrit | Merged openstack/diskimage-builder master: Use x86 architeture specific grub2 packages for RHEL https://review.opendev.org/681889 | 07:52 |
| openstackgerrit | Merged openstack/diskimage-builder master: Move doc related modules to doc/requirements.txt https://review.opendev.org/628466 | 07:52 |
| *** apetrich has joined #openstack-infra | 07:52 | |
| *** ykarel is now known as ykarel|lunch | 07:56 | |
| *** priteau has joined #openstack-infra | 07:57 | |
| *** Tengu has quit IRC | 07:59 | |
| *** tkajinam_ has quit IRC | 08:01 | |
| *** Tengu has joined #openstack-infra | 08:03 | |
| *** gfidente has quit IRC | 08:06 | |
| *** dchen has quit IRC | 08:13 | |
| *** ccamacho has joined #openstack-infra | 08:14 | |
| *** ccamacho has quit IRC | 08:14 | |
| openstackgerrit | Andreas Jaeger proposed openstack/diskimage-builder master: Only install doc requirements if needed https://review.opendev.org/681991 | 08:17 |
| *** ccamacho has joined #openstack-infra | 08:18 | |
| *** gfidente has joined #openstack-infra | 08:25 | |
| *** snapiri has joined #openstack-infra | 08:26 | |
| evrardjp | good morning | 08:29 |
| evrardjp | I will have a look | 08:29 |
| evrardjp | AJaeger: I think we agreed that we need to exercise more going that way. The problem was a chain of dependencies to be settled before this, and those aren't done yet. But I will update the minimum thing I have to do | 08:30 |
| evrardjp | today | 08:31 |
| *** roman_g has joined #openstack-infra | 08:34 | |
| evrardjp | wow that's hardly english | 08:34 |
| evrardjp | I meant that 1) Dependencies have to be done first 2) we need to exercise more 3) so we concluded that there is no urgency afaik for this, yet we should do it. | 08:35 |
| *** xenos76 has joined #openstack-infra | 08:37 | |
| *** e0ne has joined #openstack-infra | 08:38 | |
| *** gfidente has quit IRC | 08:39 | |
| AJaeger | evrardjp: understood | 08:41 |
| *** gfidente has joined #openstack-infra | 08:43 | |
| *** markvoelker has joined #openstack-infra | 08:44 | |
| *** exsdev0 has joined #openstack-infra | 08:44 | |
| *** derekh has joined #openstack-infra | 08:45 | |
| *** exsdev has quit IRC | 08:45 | |
| *** exsdev0 is now known as exsdev | 08:45 | |
| *** markvoelker has quit IRC | 08:49 | |
| *** ralonsoh has quit IRC | 08:51 | |
| *** ralonsoh has joined #openstack-infra | 08:55 | |
| *** jaosorior has quit IRC | 09:00 | |
| *** ykarel|lunch is now known as ykarel | 09:08 | |
| *** udesale has joined #openstack-infra | 09:15 | |
| *** Florian has quit IRC | 09:19 | |
| *** FlorianFa has joined #openstack-infra | 09:19 | |
| *** lajoskatona has quit IRC | 09:31 | |
| *** lajoskatona has joined #openstack-infra | 09:35 | |
| *** iurygregory has joined #openstack-infra | 09:43 | |
| *** ralonsoh has quit IRC | 09:48 | |
| *** ralonsoh has joined #openstack-infra | 09:48 | |
| *** ralonsoh has quit IRC | 09:50 | |
| *** ralonsoh has joined #openstack-infra | 09:53 | |
| *** udesale has quit IRC | 09:56 | |
| *** udesale has joined #openstack-infra | 09:57 | |
| *** tkajinam has joined #openstack-infra | 10:05 | |
| *** ociuhandu has joined #openstack-infra | 10:06 | |
| *** ociuhandu has quit IRC | 10:07 | |
| *** pcaruana has quit IRC | 10:11 | |
| *** shachar has joined #openstack-infra | 10:20 | |
| *** snapiri has quit IRC | 10:23 | |
| *** ociuhandu has joined #openstack-infra | 10:23 | |
| *** ociuhandu has quit IRC | 10:28 | |
| *** pgaxatte has quit IRC | 10:34 | |
| donnyd | lajoskatona: FN has expanded labels | 10:38 |
| *** ociuhandu has joined #openstack-infra | 10:38 | |
| *** ociuhandu has quit IRC | 10:44 | |
| lajoskatona | donnyd:Hi, could you explain this please, I am not an expert of infra | 10:52 |
| *** elod has quit IRC | 10:54 | |
| donnyd | You can run an experimental job against the expanded labels | 10:54 |
| *** elod has joined #openstack-infra | 10:55 | |
| donnyd | https://opendev.org/openstack/project-config/src/branch/master/nodepool/nl02.openstack.org.yaml#L356 | 10:56 |
| lajoskatona | donnyd: thanks, just to be on the same page. | 10:58 |
| lajoskatona | donnyd: I add nodepool: ubuntu-bionic-expanded which as I see has 16G memory, and zuul will build the VM accordingly? | 11:00 |
| donnyd | Nodepool will route your job to the appropriate provider that has that label | 11:01 |
| lajoskatona | donnyd: ok, I check with it. Thanks again | 11:02 |
| donnyd | Just a reminder, only do this for experimental purposes. Not all the providers have this label | 11:02 |
| lajoskatona | donnyd: ok, I come back to infra if I have results | 11:05 |
| *** jbadiapa has quit IRC | 11:08 | |
| openstackgerrit | Donny Davis proposed openstack/project-config master: Fixes for FN seem to have worked - scaling up https://review.opendev.org/682026 | 11:13 |
| AJaeger | fungi, frickler, can you confirm and want to +2A? ^ | 11:14 |
| AJaeger | donnyd: thanks | 11:14 |
| donnyd | AJaeger: In testing on my end it all was working much mo betta... so hopefully this is it | 11:15 |
| donnyd | won't know 100% till it gets there in scale | 11:15 |
| *** lpetrut has quit IRC | 11:20 | |
| *** iurygregory has quit IRC | 11:23 | |
| *** pcaruana has joined #openstack-infra | 11:24 | |
| *** calbers has joined #openstack-infra | 11:32 | |
| *** lucasagomes has joined #openstack-infra | 11:34 | |
| *** rh-jelabarre has joined #openstack-infra | 11:39 | |
| AJaeger | sure ;) | 11:39 |
| *** sshnaidm|rover is now known as sshnaidm|off | 11:40 | |
| *** calbers has quit IRC | 11:40 | |
| *** udesale has quit IRC | 11:40 | |
| *** udesale has joined #openstack-infra | 11:41 | |
| *** ociuhandu has joined #openstack-infra | 11:41 | |
| *** lpetrut has joined #openstack-infra | 11:42 | |
| *** ociuhandu has quit IRC | 11:42 | |
| *** jpena is now known as jpena|lunch | 11:48 | |
| *** lpetrut has quit IRC | 11:59 | |
| *** lpetrut has joined #openstack-infra | 11:59 | |
| *** rkukura has quit IRC | 12:01 | |
| *** pgaxatte has joined #openstack-infra | 12:03 | |
| *** markvoelker has joined #openstack-infra | 12:04 | |
| *** apetrich has quit IRC | 12:08 | |
| *** goldyfruit has quit IRC | 12:12 | |
| *** apetrich has joined #openstack-infra | 12:16 | |
| *** ociuhandu has joined #openstack-infra | 12:22 | |
| *** tkajinam has quit IRC | 12:25 | |
| *** jaosorior has joined #openstack-infra | 12:27 | |
| *** Goneri has joined #openstack-infra | 12:32 | |
| *** ociuhandu has quit IRC | 12:32 | |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-tox-output: introduce zuul_use_fetch_output https://review.opendev.org/681864 | 12:35 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-subunit-output: introduce zuul_use_fetch_output https://review.opendev.org/681882 | 12:35 |
| *** rlandy has joined #openstack-infra | 12:35 | |
| *** ociuhandu has joined #openstack-infra | 12:39 | |
| *** dave-mccowan has joined #openstack-infra | 12:44 | |
| *** rf0lc0 has joined #openstack-infra | 12:44 | |
| *** jbadiapa has joined #openstack-infra | 12:44 | |
| sean-k-mooney | fungi: so this is a dumb idea but we were talking about alternitive way of scheduling jobs yesterday | 12:44 |
| sean-k-mooney | for any given project in the could we order its pending jobs by a kind of weighted average of the review priority field in gerrit and the lenght of time it has been in the pipeline while still doing round robin across projects within the pipeline | 12:46 |
| *** lpetrut has quit IRC | 12:48 | |
| sean-k-mooney | basically score = (1 + review-priority-labael) * time in pipeline | 12:48 |
| sean-k-mooney | then withing a pipelien group by project and sort the project jobs by score | 12:49 |
| sean-k-mooney | that would allow project teams to set review priority to +2 to merge to give it higher pirorty | 12:50 |
| sean-k-mooney | e.g. a job with a +2 priority that had been wiait for 1 hour would have the same score as a job with a 0 pirorty that had been waiting for 3 | 12:51 |
| pabelanger | sean-k-mooney: zuul as support for relative priority today, but is based on the change queue a project is part of: https://zuul-ci.org/docs/zuul/admin/components.html#attr-scheduler.relative_priority | 12:51 |
| pabelanger | I want to say, if you are in the integrated queue, it is also weighted against the other projects in it too | 12:52 |
| pabelanger | that works well, to let smaller projects access to resources | 12:52 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-tox-output: introduce zuul_use_fetch_output https://review.opendev.org/681864 | 12:52 |
| sean-k-mooney | yep we want to keep that | 12:52 |
| sean-k-mooney | but ff is today/yesterday | 12:52 |
| sean-k-mooney | and it woudl have been nice to say merge these patches first | 12:53 |
| sean-k-mooney | to avoid conflict | 12:53 |
| sean-k-mooney | and these othere one later | 12:53 |
| *** lpetrut has joined #openstack-infra | 12:53 | |
| sean-k-mooney | we tried to do that by not approving things but that does not always work | 12:53 |
| sean-k-mooney | pabelanger: but ya it would effectily be like the relative_priortiy option but instead fo operating at the pipeline level it would operate on the individual pathces. | 12:54 |
| pabelanger | sean-k-mooney: yah, in this case, an option is to abandon or ask humans not to add new patches to change queue, to all the important one to get nodeset first. However, that is a manual step. Long term, I've mostly found, more resources also fixes the issue :) | 12:54 |
| *** EmilienM is now known as EvilienM | 12:55 | |
| sean-k-mooney | pabelanger: yes throwing more cores (but human and machine) can help but both are limited resouces | 12:55 |
| AJaeger | and a gate that is stable ;) So bug fixes instead of unstable features :) | 12:55 |
| pabelanger | AJaeger: +100 | 12:56 |
| sean-k-mooney | AJaeger: actully in this case sepecicaly the issue has not been stablity | 12:56 |
| sean-k-mooney | it was more we had 3 feature that had trivial merge confict | 12:57 |
| sean-k-mooney | like litrally white space | 12:57 |
| sean-k-mooney | soe we ended up puting all 3 feature into 1 chain of patches to avoid that | 12:57 |
| sean-k-mooney | then a seperate feature merged and put the chain into merge confilct | 12:57 |
| *** ociuhandu has quit IRC | 12:58 | |
| AJaeger | sean-k-mooney: you can check *before* approving for conflicts, there's a tab in gerrit for it. | 12:58 |
| sean-k-mooney | yes i know | 12:58 |
| *** dave-mccowan has quit IRC | 12:58 | |
| AJaeger | sean-k-mooney: and I doubt that your proposal above would have helped with this specific case - or would it? | 12:58 |
| sean-k-mooney | no | 12:58 |
| sean-k-mooney | well it might | 12:59 |
| sean-k-mooney | in that the big chain could have been marked a high pirority | 12:59 |
| sean-k-mooney | and the rest as not | 12:59 |
| *** jpena|lunch is now known as jpena | 12:59 | |
| sean-k-mooney | soe it may have changed the order of mergeing | 12:59 |
| sean-k-mooney | anyway it was just a thought of something we could maybe try | 13:00 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-output-openshift: initial role https://review.opendev.org/682044 | 13:05 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-subunit-output: introduce zuul_use_fetch_output https://review.opendev.org/681882 | 13:05 |
| sean-k-mooney | also i proably should have put that in the zuul channel sorry | 13:05 |
| fungi | i could see maybe working additional prioritization criteria into independent pipelines. it might also work on the inactive changes outside the window of a dependent pipeline, but reprioritizing changes which have already started builds would waste resources | 13:06 |
| fungi | since dependent pipelines are sequenced | 13:06 |
| *** ociuhandu has joined #openstack-infra | 13:07 | |
| fungi | adjusting the order of changes in them necessarily means discarding prior results or in progress builds | 13:07 |
| sean-k-mooney | fungi: ya i was more thining of just the initall ordering | 13:07 |
| sean-k-mooney | once they start there ordering would be fixed | 13:07 |
| sean-k-mooney | this was mainly a suggestion for independent pipeline like check | 13:08 |
| sean-k-mooney | sicne all patche have to go through check it also indirectly influence gate | 13:08 |
| fungi | well, the initial ordering (until you exceed the active window) is determined by chronological events. there's no way for zuul to prededict that you're going to approve something of higher priority in the future so it starts testing things as soon as it is able | 13:09 |
| sean-k-mooney | but in a positive way by priorities what gets sent to gate | 13:09 |
| sean-k-mooney | right but it currenlty round robings between ques of jobs per porject within a pipleine right | 13:09 |
| pabelanger | there is also the issue, that nodepool is the one who handles node-requests, you could ask for something to be higher, but if that nodeset doesn't come online right away, the other patches will still get their nodesets first | 13:09 |
| sean-k-mooney | and pull the next job of the top of that queue | 13:09 |
| sean-k-mooney | im suggesing order the queue not by time of submission | 13:10 |
| sean-k-mooney | but by the score above with is time in the queue* priority | 13:10 |
| sean-k-mooney | if we do an insertion sort we only update that order once | 13:10 |
| sean-k-mooney | when each patch is submitted | 13:11 |
| *** Tengu has quit IRC | 13:11 | |
| *** Tengu has joined #openstack-infra | 13:11 | |
| sean-k-mooney | it really would be an ordering of the jobs sets rather then indivugal jobs too | 13:12 |
| pabelanger | right, but today, even in realative priority, if you had A and B, if both ask for nodes from nodepool. We don't block B until A gets them, we send request for both. And if A nodeset fail, due to cloud issue, B will still run before A | 13:12 |
| *** ociuhandu has quit IRC | 13:12 | |
| sean-k-mooney | as we want the set of jobs to run together | 13:12 |
| fungi | yeah, but inserting a change ahead of other changes of lower priority which are already being tested necessarily means discarding those builds | 13:12 |
| sean-k-mooney | fungi: as i said im only suggsing doing this for change that not started being tested | 13:13 |
| AJaeger | sean-k-mooney: Your approach might work in theory - but our tooling is not able t ohandle it without major changes. Your idea is to delay asking for nodes and recalculate priorities every time a new change is added. What we do today is calculate only when a new change is added - and not afterwards. | 13:13 |
| AJaeger | So, that is also a different complexity and would be a far longer scheduling computation. | 13:14 |
| openstackgerrit | Merged openstack/project-config master: Fixes for FN seem to have worked - scaling up https://review.opendev.org/682026 | 13:14 |
| sean-k-mooney | AJaeger: ya i had not looked at the zuul code | 13:14 |
| fungi | that might also mean starting to defer, or unnecessarily redoing, merge tasks too | 13:14 |
| sean-k-mooney | but its just somehting that i thought of after our conversation last night. | 13:15 |
| fungi | which is why independent pipelines might be easier to tackle for something like that | 13:15 |
| sean-k-mooney | i was not expecting imediate action but i was wondering how feasible it might be | 13:15 |
| sean-k-mooney | fungi: isnt the check an independent pipeline? | 13:15 |
| *** ociuhandu has joined #openstack-infra | 13:16 | |
| fungi | yes, we've been muddling that and discussions of "shared queues" though | 13:16 |
| sean-k-mooney | ah | 13:16 |
| *** iurygregory has joined #openstack-infra | 13:16 | |
| fungi | and activity windows | 13:16 |
| pabelanger | TBH: having some humans work to see why we have such a large rate of failure when launching nodes in nodepool, also helps this situation. EG: http://grafana.openstack.org/d/rZtIH5Imz/nodepool?orgId=1&fullscreen&panelId=17&from=now-7d&to=now I would spend a lot of time working to keep that at zero (when day job was working in openstack). That has a huge impact on how efficient jobs work in nodepool, | 13:16 |
| pabelanger | given how limited resources are too | 13:17 |
| sean-k-mooney | i used queue in a generic sense of things waithing int check that have not started | 13:17 |
| sean-k-mooney | not in the zuul sense which i should learn about at sometime | 13:17 |
| pabelanger | http://grafana.openstack.org/d/rZtIH5Imz/nodepool?orgId=1&fullscreen&panelId=17&from=now-5y&to=now is another graph | 13:17 |
| pabelanger | that could be cloud side, or make some issues with specific operating systems. | 13:18 |
| pabelanger | maybe* | 13:18 |
| sean-k-mooney | ya that is more of an operaational task that never ends | 13:18 |
| clarkb | pabelanger: a large chunk of it is failed boots in vexxhost due to volume leaks and quota being accounted wrong | 13:18 |
| *** mriedem has joined #openstack-infra | 13:18 | |
| sean-k-mooney | i have no doubts that if we had 0 failed node builds the gate woudl be fast | 13:19 |
| clarkb | its a known issue, shrews is looking into our side of it | 13:19 |
| pabelanger | clarkb: yah, that is something I am hoping to work on this / next week. It also hits un hard with NODE_FAILUREs | 13:19 |
| *** whoami-rajat has quit IRC | 13:19 | |
| sean-k-mooney | *faster | 13:19 |
| AJaeger | config-core, could you review https://review.opendev.org/681785 https://review.opendev.org/681276 https://review.opendev.org/#/c/681259/ https://review.opendev.org/681361 and https://review.opendev.org/680901 , please? | 13:19 |
| AJaeger | nothing of that should impact feature freeze | 13:20 |
| clarkb | sean-k-mooney: if we order the queue by subjective priority everyone will set their change to be highest priority | 13:20 |
| clarkb | you see the same thing happen in ticket queues and bug trackers | 13:20 |
| sean-k-mooney | clarkb: i think that field is only settabel by the core team | 13:20 |
| clarkb | it makes the field pretty useless when you tie it to expected processing time | 13:21 |
| AJaeger | sean-k-mooney: I'm core, so I set it on my own changes ;) | 13:21 |
| sean-k-mooney | hehe well that is your privledge | 13:21 |
| Shrews | clarkb: the volume leak, I'm convinced until somebody else has proof otherwise, is not something caused by nodepool. what i'm looking into now is the side effects of that (image leaks caused by the volume remaining in use) | 13:22 |
| AJaeger | sean-k-mooney: I think FF is special, let's not over-optimize for it... I think we can do more to get jobs stable all the time and that will help a lot in this time. | 13:22 |
| sean-k-mooney | but the whole idea was to give core an extra knob they could tweak on a per patch basis beyound witholding a +w | 13:22 |
| clarkb | Shrews: thanks and ya would not surprise me if it were a nova and or cinder problem | 13:22 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: DNM: test tox-py36 on openshift node https://review.opendev.org/682049 | 13:22 |
| clarkb | sean-k-mooney: to improve review visibility | 13:22 |
| pabelanger | clarkb: Shrews: Agree, but I do think adding a quota check, if enough volumes free is a good idea | 13:23 |
| clarkb | "if you want to review the important changes thid is where you find them" | 13:23 |
| sean-k-mooney | thid? | 13:24 |
| clarkb | sorry "this" | 13:24 |
| sean-k-mooney | this | 13:24 |
| sean-k-mooney | ya that is what review priortiy was intened to be | 13:25 |
| sean-k-mooney | we dont use it in nova currently but we might at some point | 13:25 |
| clarkb | but ya I agree with AJaeger this is the time of the cycle where we feel the pain of our ci debt | 13:26 |
| clarkb | if we paid that down continuously we'd be in amuch better place | 13:26 |
| *** jaosorior has quit IRC | 13:26 | |
| pabelanger | tripleo used to (or maybe still) have this problem. They'd end up abandoning all the open patches, then only approve ones needed to fix tests. As crude as that is, it would allow them to order things, in current tooling | 13:26 |
| clarkb | rather than optimizethe tools for "our code is flaky and cant pass CI" lets optimize for making good software then when we dog food that software we dont leak volumes preventing us from booting jnstances | 13:27 |
| fungi | the volume leak in vexxost is looking likely to be nova and cinder pointing fingers over which should be responsible for making sure volume attachment records are sane when servers are deleted | 13:27 |
| fungi | fixing that in openstack would directly improve our throughput | 13:27 |
| pabelanger | +1 | 13:27 |
| *** goldyfruit has joined #openstack-infra | 13:28 | |
| fungi | also known as "people run our software, and the bugs we haven't fixed have real-world consequences" | 13:28 |
| smcginnis | I haven't seen the full discussion. Why is it that nova isn't deleting the attachment but then trying to delete the volume? | 13:28 |
| lajoskatona | donnyd: How can I reference these expanded labels from my job definition, like here: https://review.opendev.org/#/c/672925/19/.zuul.d/jobs.yaml@115 ? | 13:29 |
| fungi | nova doesn't seem to try to delete the volume. it sounds (from what mnaser is saying) is that if there's an error then nova just logs that and continues on its merry way | 13:29 |
| fungi | i should say, doesn't re-try to delete | 13:29 |
| smcginnis | I guess getting to the root of that error is the key. Cinder won't spontaneously decide to clean things up without someone telling it to. | 13:30 |
| fungi | yep, and nova probably shouldn't consider the instance truly deleted if it hasn't gotten confirmation from cinder | 13:30 |
| fungi | but... the devil is in the details, i'm sure | 13:31 |
| fungi | point being, there are bugs in openstack which we haven't fixed, are deployed in service providers who are donating resources to the testing of openstack, and so we directly see the result of these deployed openstack bugs impact the testing throughput of new patches to openstack | 13:32 |
| *** eharney has joined #openstack-infra | 13:33 | |
| fungi | so it's not just testing-related bugs which impact our ability to test changes | 13:33 |
| AJaeger | it's also small things like using promote jobs that don't need jobs and don't rebuild artifacts ;) - that saves two or three nodes per merge currently (releasenotes, docs, api-ref) | 13:42 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-sphinx-tarball: introduce zuul_use_fetch_output https://review.opendev.org/681870 | 13:42 |
| donnyd | lajoskatona: I'm out at the moment, be back in a bit | 13:44 |
| lajoskatona | donnyd: ok, thanks, I go for my sons as well now :-) | 13:45 |
| openstackgerrit | Jeremy Stanley proposed opendev/git-review master: Support spaces in topic https://review.opendev.org/681906 | 13:46 |
| clarkb | AJaeger: also speeding up jobs helps a lot. This is why I spent a little time to show that devstack could save a bunch of time reworking its api interactions | 13:46 |
| *** efried has joined #openstack-infra | 13:47 | |
| AJaeger | indeed, clarkb ... | 13:47 |
| AJaeger | can we start an FAQ about scheduling? If everybody that wanted to discuss scheduling in the last 4 weeks would have spend a day improving jobs, we would be in a much better situation ;) | 13:49 |
| *** xenos76 has quit IRC | 13:50 | |
| *** aaronsheffield has joined #openstack-infra | 13:52 | |
| *** kjackal has quit IRC | 13:58 | |
| *** kaiokmo has quit IRC | 14:01 | |
| *** ykarel is now known as ykarel|afk | 14:01 | |
| fungi | well, it starts out as people complaining about scheduling because they feel the algorithm unfairly penalizes them, then others explain the scheduling and the hard choices which were made, and then it evolves into wanting to discuss optimizations to that scheduling | 14:02 |
| *** ykarel|afk has quit IRC | 14:10 | |
| *** kaiokmo has joined #openstack-infra | 14:13 | |
| *** goldyfruit has quit IRC | 14:14 | |
| mriedem | clarkb: fyi, i screwed up on that gate fix the other day and the fix for my fix is https://review.opendev.org/682025 | 14:15 |
| mriedem | in case we need to promote | 14:15 |
| mriedem | that's for http://status.openstack.org/elastic-recheck/#1843615 | 14:15 |
| AJaeger | mriedem: should fungi enqueue directly to gate (not promote) - it's still in check... | 14:17 |
| mriedem | probably? it hasn't gotten a node in check yet | 14:20 |
| mriedem | and since it's nova, it probably won't for 12+ hours | 14:20 |
| fungi | can do | 14:20 |
| fungi | just a sec | 14:20 |
| clarkb | note that isnt nova specific and currently its ~5.5 hours | 14:21 |
| *** hrw has joined #openstack-infra | 14:21 | |
| clarkb | but ya if it fixes gate issues lets get them enqueued | 14:21 |
| hrw | morning | 14:21 |
| hrw | can mirror.bhs1.ovh.openstack.org be forced to refresh ubuntu mirror? | 14:22 |
| fungi | mriedem: it's enqueued now. we can also promote it to the front of the gate if that will help get things moving faster in the integrated gate queue | 14:22 |
| *** whoami-rajat has joined #openstack-infra | 14:23 | |
| AJaeger | hrw: all our mirrors are in sync - why do you need to update this specific one and not the others? | 14:23 |
| fungi | hrw: all the mirrors should be in sync, they're sharing one network filesystem | 14:23 |
| AJaeger | hrw: and what is missing? | 14:23 |
| clarkb | hrw it should update every ~4 hours but looks like it got stuck a couple days ago | 14:23 |
| mriedem | fungi: that will reset the gate won't it? | 14:23 |
| clarkb | AJaeger: ^ I'm guessing its not a specific mirror just that it hasntupdated in acouple days | 14:23 |
| fungi | mriedem: yes, so it's not a tradeoff to be taken lightly | 14:23 |
| hrw | INFO:kolla.common.utils.kolla-toolbox: python3-dev : Depends: libpython3-dev (= 3.6.7-1~18.04) but it is not going to be installed | 14:23 |
| mriedem | yeah let's just let it ride for now | 14:23 |
| clarkb | likely the afs release and stale lock issue | 14:23 |
| hrw | INFO:kolla.common.utils.kolla-toolbox: Depends: python3.6-dev (>= 3.6.7-1~) but it is not going to be installed | 14:23 |
| hrw | AJaeger: CI gets stuck :( | 14:24 |
| clarkb | hrw: hrm the mirror should always be consistent when it is published. why us it not being installed? | 14:24 |
| hrw | AJaeger: from what I see ovh mirrors have older packages than ubuntu:bionic container | 14:24 |
| hrw | clarkb: container has newer package than mirror == installation fails | 14:25 |
| clarkb | oh I see you areupdating acontainer built fron another source | 14:25 |
| hrw | yes | 14:25 |
| hrw | we fetch official container and then install packages in it. | 14:25 |
| hrw | works unless run on ovh | 14:26 |
| clarkb | ovh has the same packages as everyone else | 14:26 |
| clarkb | we use a shared filesystem (afs) to host the data | 14:26 |
| hrw | ok | 14:27 |
| fungi | i'm assuming hrw looked at a failure which occurred in ovh, assumed it was an ovh-specific problem, and didn't realize it's affecting our entire mirror network | 14:27 |
| hrw | fungi: +1 | 14:27 |
| fungi | so for future reference, explaining the issue you're encountering and providing examples first rather than jumping to conclusions about what needs to be done helps avoid a lot of confusion | 14:27 |
| hrw | right, sorry about that | 14:28 |
| *** panda|ruck has quit IRC | 14:28 | |
| hrw | https://pastebin.com/1zEMBwbQ shows the issue | 14:28 |
| *** panda has joined #openstack-infra | 14:29 | |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-sphinx-tarball: introduce zuul_use_fetch_output https://review.opendev.org/681870 | 14:29 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-translation-output: introduce zuul_use_fetch_output https://review.opendev.org/681887 | 14:29 |
| hrw | libexpat1 from container is newer than one in mirror. we want to install python3-dev and it refuses because of it. If I do same in ubuntu:bionic locally with ubuntu mirrors then it works | 14:29 |
| clarkb | I think it hasnt updated since I manually updatedit I'm fairly certain I r eleased the update server lock but can double check | 14:30 |
| fungi | right, so to clarify, the problem seems to stem from using images which are built from newer packages than those currently present in our mirror | 14:30 |
| hrw | fungi: yes | 14:30 |
| fungi | and yes, i expect clarkb is on the money that it's because mirror updates have hung | 14:30 |
| fungi | and this would be affecting all our mirror of ubuntu | 14:31 |
| clarkb | "The lock file '/afs/.openstack.org/mirror/ubuntu/db/lockfile' already exists." | 14:32 |
| *** xek has joined #openstack-infra | 14:32 | |
| clarkb | vos listvldb does not show it as being locked though | 14:33 |
| clarkb | oh wait that is a reprepro lock I think | 14:33 |
| fungi | yep | 14:34 |
| *** goldyfruit has joined #openstack-infra | 14:34 | |
| fungi | maybe a previous reprepro run was terminated ungracefully and left that dangling? | 14:34 |
| clarkb | possibly from the reboot that was done on that server? | 14:35 |
| fungi | created Sep 10 18:33 | 14:35 |
| *** xek_ has joined #openstack-infra | 14:35 | |
| fungi | or last updated at least | 14:35 |
| hrw | fungi: fits mirror's age | 14:35 |
| clarkb | is that something we can simply rm then? | 14:35 |
| fungi | yeah, if it was rebooted mid-run for reprepro that would probably explain it | 14:35 |
| fungi | should be able to rm and rerun the script | 14:36 |
| *** xek has quit IRC | 14:37 | |
| fungi | reboot system boot Tue Sep 10 16:51 still running 0.0.0.0 | 14:37 |
| fungi | acording to last | 14:37 |
| fungi | so that was timestamped a couple hours *after* the reboot? strange | 14:38 |
| fungi | seems to correspond with the duration uptime reports, so i don't think the timestamp in wtmp is way off or anything | 14:39 |
| clarkb | fwiw I've grabbed the mirror update lock file and removed the reprepro lock file and will manually run the update now | 14:39 |
| fungi | thanks | 14:39 |
| *** goldyfruit_ has joined #openstack-infra | 14:42 | |
| hrw | thank you | 14:42 |
| *** rcernin has quit IRC | 14:42 | |
| *** e0ne has quit IRC | 14:43 | |
| *** lpetrut has quit IRC | 14:43 | |
| *** goldyfruit has quit IRC | 14:44 | |
| *** ociuhandu has quit IRC | 14:45 | |
| *** munimeha1 has joined #openstack-infra | 14:47 | |
| *** mattw4 has joined #openstack-infra | 14:48 | |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-javascript-content-tarball: introduce zuul_use_fetch_output https://review.opendev.org/681903 | 14:48 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-sphinx-output: introduce zuul_use_fetch_output https://review.opendev.org/681905 | 14:48 |
| *** xenos76 has joined #openstack-infra | 14:49 | |
| *** rkukura has joined #openstack-infra | 14:51 | |
| clarkb | AJaeger: re faq what I've tried to do in the past is send periodic updates to the mailing list explaining the current situation and why improving software reliability is likely to have the greatest impact | 14:56 |
| *** ociuhandu has joined #openstack-infra | 14:59 | |
| *** armax has joined #openstack-infra | 15:02 | |
| clarkb | unfortunately I'm not sure how effective that has been | 15:02 |
| *** ociuhandu has quit IRC | 15:03 | |
| *** xenos76 has quit IRC | 15:03 | |
| hrw | thanks for mirror refresh - installing python3-dev works so we can continue fixing errors shown us by CI | 15:06 |
| clarkb | hrw: fwiw its still running (the afs publishign step is where we are at so hopefulyl done soon) | 15:08 |
| hrw | clarkb: in worst case it will one more recheck. | 15:08 |
| *** pgaxatte has quit IRC | 15:09 | |
| AJaeger | clarkb: there have been questions/discussions about fail-fast, reverify - and also the requirement to run through check first. I was thinking of documenting these. And adding a node about stable gates... | 15:09 |
| * AJaeger will be back later | 15:10 | |
| *** mattw4 has quit IRC | 15:11 | |
| *** ociuhandu has joined #openstack-infra | 15:13 | |
| *** pmatulis has joined #openstack-infra | 15:15 | |
| *** pmatulis has left #openstack-infra | 15:15 | |
| *** jamesmcarthur has joined #openstack-infra | 15:15 | |
| *** ykarel|afk has joined #openstack-infra | 15:16 | |
| *** ociuhandu has quit IRC | 15:18 | |
| *** tesseract has quit IRC | 15:25 | |
| *** igordc has joined #openstack-infra | 15:25 | |
| *** ociuhandu has joined #openstack-infra | 15:26 | |
| *** xenos76 has joined #openstack-infra | 15:26 | |
| *** igordc has quit IRC | 15:27 | |
| *** igordc has joined #openstack-infra | 15:27 | |
| *** jtomasek has quit IRC | 15:28 | |
| *** dayou has quit IRC | 15:28 | |
| *** udesale has quit IRC | 15:30 | |
| *** udesale has joined #openstack-infra | 15:31 | |
| *** weshay|ruck has quit IRC | 15:31 | |
| *** igordc has quit IRC | 15:32 | |
| *** ociuhandu has quit IRC | 15:33 | |
| *** rkukura has quit IRC | 15:33 | |
| *** dklyle has quit IRC | 15:35 | |
| fungi | AJaeger: the choices we've made for scheduling algorithm are probably worth explaining too | 15:36 |
| *** dklyle has joined #openstack-infra | 15:36 | |
| clarkb | caught one of those swift errors. corvus' hunch was correct it is the get_container that is failing | 15:39 |
| clarkb | http://paste.openstack.org/show/775777/ | 15:39 |
| openstackgerrit | Clark Boylan proposed zuul/zuul-jobs master: Retry container gets in upload-logs-swift https://review.opendev.org/682091 | 15:39 |
| *** ykarel|afk is now known as ykarel|away | 15:39 | |
| clarkb | corvus: ^ thats an attempt at handling it | 15:39 |
| *** dayou has joined #openstack-infra | 15:40 | |
| *** ociuhandu has joined #openstack-infra | 15:42 | |
| clarkb | ubuntu mirror update has completed successfully from what I can tell and there is no reprepro lock file remaining | 15:42 |
| clarkb | I've releaed all the locks I had held to do that | 15:42 |
| clarkb | hrw: ^ fyi | 15:46 |
| *** ociuhandu has quit IRC | 15:46 | |
| *** gfidente is now known as gfidente|afk | 15:50 | |
| *** ramishra has quit IRC | 15:51 | |
| *** rmcallis has joined #openstack-infra | 15:55 | |
| corvus | clarkb: i think you leed a lambda | 15:59 |
| corvus | and by leed i mean need | 15:59 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-javascript-content-tarball: introduce zuul_use_fetch_output https://review.opendev.org/681903 | 16:01 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-sphinx-output: introduce zuul_use_fetch_output https://review.opendev.org/681905 | 16:01 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul-jobs master: fetch-coverage-output: introduce zuul_use_fetch_output https://review.opendev.org/681904 | 16:01 |
| openstackgerrit | Clark Boylan proposed openstack/infra-manual master: Document why jobs queues are slow https://review.opendev.org/682098 | 16:01 |
| clarkb | corvus: oh right | 16:01 |
| clarkb | AJaeger: fungi ^ thats a rough first draft (I didn't even build it locally, probably should've) | 16:01 |
| *** calbers has joined #openstack-infra | 16:02 | |
| *** rlandy is now known as rlandy|brb | 16:02 | |
| hrw | clarkb: thanks! | 16:02 |
| clarkb | looks like the mirror.ubuntu release still causing stale cache problems https://e63daf97f32f2cebe260-b80014e5a7a6453c822c4dc8f22159da.ssl.cf1.rackcdn.com/681829/1/gate/openstack-tox-py37/fb0ef49/job-output.txt ? | 16:05 |
| clarkb | that host is running openafs and not kafs iirc | 16:05 |
| *** owalsh has quit IRC | 16:11 | |
| smcginnis | Howdy infra folks. We got a tag-releases job failure. Looks like a mirror issue that I think I saw being discussed earlier. | 16:13 |
| smcginnis | Should we hold off on any releases? Or are things cleared up? | 16:13 |
| smcginnis | If cleared up, can we get this reenqueued? https://storage.bhs1.cloud.ovh.net/v1/AUTH_dcaab5e32b234d56b626f72581e3644c/zuul_opendev_logs_c95/765061f2ad4b965059c33e2577547ac952344ee3/release-post/tag-releases/c95672e/job-output.txt | 16:13 |
| clarkb | smcginnis: we can check the files directly to see if afs has caught up | 16:14 |
| smcginnis | Thanks | 16:15 |
| *** mattw4 has joined #openstack-infra | 16:15 | |
| clarkb | I just have to remember where it lists those fiel sizes and hashes | 16:15 |
| clarkb | fungi: ^ you probably know off the top of your head | 16:16 |
| openstackgerrit | Clark Boylan proposed zuul/zuul-jobs master: Retry container gets in upload-logs-swift https://review.opendev.org/682091 | 16:17 |
| *** mriedem is now known as mriedem_afk | 16:19 | |
| clarkb | I can confirm that the values are stil not what are expected according to the job | 16:19 |
| clarkb | but I think I also need to check the thing that gives us the expected values | 16:19 |
| clarkb | the release file | 16:21 |
| clarkb | b6177c2e199dc2374792b3ad3df2611643a2d32211c88cff8cb44192864aba32 1033953 main/binary-amd64/Packages.gz is what releases says now for bionic-update so I think afs has caught up | 16:22 |
| *** rpittau is now known as rpittau|afk | 16:22 | |
| clarkb | smcginnis: ^ fyi | 16:22 |
| *** kjackal has joined #openstack-infra | 16:22 | |
| clarkb | that matches what I get locally if I list the ifle size and sha256sum it | 16:22 |
| *** hrw has left #openstack-infra | 16:24 | |
| *** iurygregory has quit IRC | 16:24 | |
| *** eharney has quit IRC | 16:25 | |
| jrosser | Did anything come of looking at the debian buster repos yesterday? exim packages failing to install.... | 16:28 |
| clarkb | jrosser: yes fungi believes the issue is we need to stop disabling buster updates repo in jobs | 16:28 |
| clarkb | jrosser: our mirror isn't keeping exim4 for both buster and buster updates because buster updates supercedes buster. And the job is likely looking for the buster package aiui | 16:28 |
| jrosser | Ok, so the setup of the node disables the updates repo? | 16:29 |
| *** owalsh has joined #openstack-infra | 16:29 | |
| clarkb | I'm not sure. I know when buster was first brought up the jobs failed because buster updates had no content. updates must've been disabled somewhere. Not sure if in the base jobs or your jobs | 16:30 |
| jrosser | For this I just flipped the nodeset from stretch to buster | 16:31 |
| jrosser | Well actually I had to define a Mideast, there doesn’t seem to be one afaik | 16:31 |
| jrosser | *nodeset | 16:31 |
| *** whoami-rajat has quit IRC | 16:32 | |
| jrosser | So it’s a job that would otherwise be fine on stretch | 16:32 |
| fungi | yeah, the problem was partly to do with reprepro: we configured it to start mirroring the buster-updates suite as soon as that appeared on debian's official mirrors (shortly after buster release day) but the suite sat empty until a few days ago. reprepro refuses to create empty suite indices, so our mirrors continued to lack a buster-updates suite and jobs which tried to pull package indices for it | 16:32 |
| fungi | were broken | 16:32 |
| AJaeger | clarkb: thanks for the writeup! | 16:32 |
| fungi | now there are packages in buster-updates, which brings a new problem... reprepro wants to only keep a certain number of versions of the same packages in the shared package pool | 16:33 |
| openstackgerrit | Donny Davis proposed openstack/project-config master: FN networking issued have been solved https://review.opendev.org/682107 | 16:33 |
| fungi | so it has deleted the older buster release packages and is only keeping the ones for the buster-updates suite | 16:33 |
| smcginnis | clarkb: Thanks. Do you think it's safe to reenqueue that failed job then? | 16:34 |
| *** owalsh has quit IRC | 16:34 | |
| donnyd | So I have been monitoring the workload now that it's at 50%, and the retransmission issue with ipv6 is solved | 16:34 |
| fungi | jrosser: clarkb: all that is to say, i think we need to figure out where the tuning knob is for number of versions of packages to keep in the pool and crank it up a bit | 16:34 |
| clarkb | fungi: or just enable buster updates in the jobs? | 16:35 |
| fungi | but also, if jobs switch to including buster-updates sources, that may fix things, yes | 16:35 |
| clarkb | fungi: we shouldn't need those older packages right? so lets leave them out | 16:35 |
| jrosser | part of the motivation for changing to buster was we’ve just switched OSA to py3 and some stuff was failing with what looked like python3.5 bugs in stretch | 16:35 |
| donnyd | 1% of packets are retransmitted which is a really good # for real world over a tunnel | 16:35 |
| clarkb | fungi: any idea where we fixed buster by disabling updates previoulsy? | 16:35 |
| fungi | clarkb: i don't think "we" did, projects which got debian-buster jobs working likely wrote out their own sources.list files | 16:36 |
| clarkb | jrosser: do you have the link to the failing job handy again? we can probably work backward from that to see what is configuring repos | 16:37 |
| *** kopecmartin is now known as kopecmartin|off | 16:38 | |
| AJaeger | interesting, https://review.opendev.org/668238 is in integrated gate and has merge conflict - but it's the *first* keystone change in the queue. Why do we keep it in the queue at all and not remove it? | 16:38 |
| jrosser | clarkb: this is it https://review.opendev.org/#/c/681777/ | 16:39 |
| clarkb | AJaeger: probably just a missing optimization | 16:40 |
| *** derekh has quit IRC | 16:40 | |
| AJaeger | jrosser: why not create debian-buster nodeset? | 16:40 |
| *** whoami-rajat has joined #openstack-infra | 16:40 | |
| jrosser | AJaeger: because I only just learn anything about this in the last couple of days :) I copied what kolla have done | 16:41 |
| AJaeger | jrosser: patch for https://opendev.org/opendev/base-jobs/src/branch/master/zuul.d/nodesets.yaml is welcome if that is something of wider scope | 16:41 |
| *** rlandy|brb is now known as rlandy | 16:42 | |
| jrosser | I can’t do that right now but will later if no one else gets there first | 16:42 |
| *** kjackal has quit IRC | 16:43 | |
| *** gyee has joined #openstack-infra | 16:44 | |
| AJaeger | cmurphy: 668238 will not merge with just +W - you need +2 as well... | 16:45 |
| *** markvoelker has quit IRC | 16:45 | |
| cmurphy | AJaeger: TIL | 16:46 |
| *** kjackal has joined #openstack-infra | 16:46 | |
| fungi | i find it annoying that rackspace has ceased mentioning instance names in incident tickets lately | 16:48 |
| fungi | now they only tell you the instance uuid and you get to guess what region to grep to figure out which one they're talking about | 16:48 |
| *** bnemec is now known as beekneemech | 16:48 | |
| *** markvoelker has joined #openstack-infra | 16:49 | |
| fungi | kdc04.openstack.org | 16:49 |
| *** jpena is now known as jpena|off | 16:49 | |
| fungi | (i ord) | 16:49 |
| fungi | er, in ord | 16:49 |
| *** cmurphy is now known as cmorpheus | 16:51 | |
| fungi | cmorpheus: is your nick a matrix reference or a sandman reference? (though i suppose "both" and "neither" could also work) | 16:52 |
| cmorpheus | fungi: i think both because i think the matrix uses it as a sandman reference | 16:53 |
| clarkb | fungi: jrosser that job actually does seem to update buster updates | 16:53 |
| fungi | cmorpheus: oh, neat! i actually never picked up on that tie-in | 16:53 |
| *** markvoelker has quit IRC | 16:53 | |
| fungi | but now that i think about it... | 16:54 |
| *** owalsh has joined #openstack-infra | 16:54 | |
| fungi | clarkb: yeah, so could be "just" using buster-updates isn't going to solve the problem. digging deeper we're mirroring debian 10 (buster) update 1 package versions for those (and deleting the original buster release versions of them) but not including them in the buster-updates package lists. i wonder why reprepro mirrored them at all if they're not for the buster-updates suite | 16:55 |
| *** piotrowskim has quit IRC | 16:56 | |
| openstackgerrit | James E. Blair proposed zuul/zuul master: WIP: Support HTTP-only Gerrit https://review.opendev.org/681936 | 16:57 |
| openstackgerrit | James E. Blair proposed zuul/zuul master: Update gerrit pagination test fixtures https://review.opendev.org/682114 | 16:57 |
| donnyd | fungi: whenever you get a chance I can help a little bit with getting jobs through the gate | 16:59 |
| donnyd | looks like everyone is pretty busy today in infra | 17:00 |
| fungi | #status log kdc04 in rax-ord rebooted at 15:46 for a hypervisor host problem, provider ticket 190913-ord-0000472 | 17:00 |
| openstackstatus | fungi: finished logging | 17:00 |
| fungi | donnyd: sure, i've been a bit scattered today, have a list of the change numbers? | 17:00 |
| fungi | infra-root: anything in particular we need to check on kdc04 following an unexpected reboot? | 17:01 |
| clarkb | fungi: the afs/kerberos docs should have server rotation notes, probably confirm the services are running as per that ? | 17:01 |
| donnyd | fungi https://review.opendev.org/#/c/682107/ | 17:01 |
| fungi | donnyd: just the one? | 17:02 |
| clarkb | fungi: https://docs.openstack.org/infra/system-config/kerberos.html#no-service-outage-server-maintenance looks like we want to double check the db propogation is working on kdc03 | 17:02 |
| donnyd | yea, just scaling FN back up to near 100% | 17:02 |
| clarkb | I think that runs in a cron so you can simply check the logs for that cron job to see if its happy post reboot | 17:02 |
| fungi | donnyd: i've approved it, thanks! | 17:02 |
| fungi | clarkb: thanks, i'll check it out | 17:03 |
| *** diablo_rojo has joined #openstack-infra | 17:04 | |
| donnyd | thanks fungi | 17:04 |
| *** xek_ has quit IRC | 17:08 | |
| donnyd | and I did some bad math before.. the number of retransmits is more around .05% - the average connection is about 500K packets deep and the number of retrans is about 350 packets (some a little less, some a little more) | 17:10 |
| donnyd | I would call that resolved | 17:10 |
| donnyd | on to the next | 17:10 |
| *** ralonsoh has quit IRC | 17:11 | |
| fungi | yep, that seems within reason | 17:12 |
| corvus | clarkb, ianw: i barely know what i'm talking about in https://review.opendev.org/681338 -- i was mostly just trying to capture what i thought was what we thought we should try next time we lose an afs fileserver since the recovery this time wasn't as smooth as we would have liked. i really don't know how to improve that text (other than spelling 'release' correctly). so can one of you either | 17:15 |
| corvus | improve it yourself or merge it? | 17:15 |
| openstackgerrit | Merged openstack/project-config master: FN networking issued have been solved https://review.opendev.org/682107 | 17:16 |
| *** xenos76 has quit IRC | 17:16 | |
| clarkb | corvus: I'll take a stab at a new patchset | 17:16 |
| clarkb | infra-root can you review the project rename stuff https://etherpad.openstack.org/p/project-renames-2019-09-10 | 17:17 |
| auristor | corvus: I must have missed something. what type of "crash" occurred? Did the volserver or fileserver process panic? Did the host lose connectivity to the disks used for vice partitions? did the host panic or other restart without a clean shutdown? was the host machine lost and the vice partitions attached to a new machine? | 17:21 |
| openstackgerrit | Clark Boylan proposed opendev/system-config master: Add docs for recovering an OpenAFS fileserver https://review.opendev.org/681338 | 17:21 |
| clarkb | corvus: ^ something like that maybe. | 17:21 |
| clarkb | auristor: we think a host provider live migration caused the host to spin out of control. It stopped responding to ssh and what we could get from snmp showed significant cpu useage and load on the host | 17:22 |
| clarkb | auristor: and ya one of the symptoms from the console of the host was complaints from the kernel about things being unresponsive for large periods of time (including the disks hosting the volumes iirc) | 17:23 |
| auristor | was it responding to rxdebug and bos status? | 17:23 |
| clarkb | it was not responding to other afs commands (vos show volume type stuff) | 17:23 |
| auristor | vos commands would talk to the volserver | 17:24 |
| auristor | the reason I ask is that the recovery procedure is dependent upon the type of crash and whether a clean shutdown could be performed. | 17:24 |
| clarkb | no clean shutdown could be performed we had to hard reboot | 17:24 |
| clarkb | vos examine $volume -localauth is what was failing | 17:25 |
| auristor | in that case volume transactions would not survive the restart and any volumes that were attached to the fileserver or volserver would be salvaged automatically the first time they are accessed | 17:25 |
| openstackgerrit | Jonathan Rosser proposed opendev/base-jobs master: Add nodeset for debian-buster https://review.opendev.org/682118 | 17:25 |
| corvus | that's why i omitted the explicit salvage op from my instructions | 17:26 |
| clarkb | gotcha | 17:26 |
| auristor | the cleanup that would be required is to identify any temporary clone volumes and manually salvage and zap them | 17:26 |
| AJaeger | clarkb, fungi, do we want a debian-buster nodeset? See 682118 ^ | 17:27 |
| corvus | but i don't know all the cases where a manual salvage would be required, eg ^ | 17:27 |
| clarkb | auristor: is that different than `bos salvage -server $FILESERVER -partition a -showlog -orphans attach -forceDAFS` ? | 17:27 |
| *** xenos76 has joined #openstack-infra | 17:27 | |
| *** priteau has quit IRC | 17:28 | |
| auristor | vos listvol the vice partitions. any volume ids that are unknown to the vl service are temporary clones | 17:28 |
| auristor | partition salvages should not be used with a dafs server | 17:29 |
| auristor | a dafs server cannot take a whole vice partition offline | 17:29 |
| jrosser | AJaeger: i didnt think it was very cool to just switch the debian-stable nodeset from stretch to buster underneath projects that are using it right now | 17:30 |
| clarkb | out of curiousity why does the flag exist then? | 17:30 |
| auristor | for individual volume salvages | 17:30 |
| auristor | are you asking about the -forceDAFS or -partition flag? | 17:31 |
| clarkb | fwiw that comes from https://lists.openafs.org/pipermail/openafs-devel/2018-May/020493.html if you want to respond to that and say you can't do that | 17:31 |
| clarkb | auristor: the -forceDAFS flag | 17:31 |
| clarkb | you just said you can't do dafs in this case so seems odd to have a flag that does it | 17:31 |
| auristor | that is for individual volume salvages | 17:31 |
| *** kjackal has quit IRC | 17:31 | |
| clarkb | ok I assume that would be a -volume instead of -partition flag then? | 17:31 |
| auristor | I said you shouldn't do a partition salvage with a dafs fileserver | 17:32 |
| auristor | the bos command has no idea what type of fileserver it is | 17:32 |
| clarkb | ok I'm confused. I was merely going off of ianw's comments and the thread he linked on the openafs mailing list | 17:35 |
| clarkb | if thats wrong (and we know that) can someone please say so on the review? | 17:35 |
| *** udesale has quit IRC | 17:36 | |
| corvus | clarkb: have we ever manually run the salvager? | 17:38 |
| clarkb | corvus: I believe ianw did in order to restore functionality of the fedora mirror (per comments on that openafs thread) however I do not know that for certain | 17:39 |
| fungi | AJaeger: we already have debian-buster (and debian-buster-arm64) nodes, so if a nodeset is necessary for people to be able to run jobs on those then i suppose it's warranted? | 17:39 |
| fungi | jrosser: i agree, replacing debian-stable without some confirmation that jobs can actually run on debian-buster nodes is probably disruptive | 17:40 |
| jrosser | I think having <>-codenane and <>-stable at the same time is useful, folks can choose to stick or get moved forward | 17:42 |
| openstackgerrit | James E. Blair proposed opendev/system-config master: Add docs for recovering an OpenAFS fileserver https://review.opendev.org/681338 | 17:42 |
| corvus | clarkb, fungi, ianw: ^ let's just merge that so we at least have some docs that tell us what to make sure is still working, even if it doesn't tell us all they ways to fix all the things that may be broken. | 17:43 |
| corvus | then when ianw is back, he can propose a change to include stuff about the salvager, and we can examine that very carefully at length | 17:43 |
| *** goldyfruit_ has quit IRC | 17:46 | |
| *** goldyfruit_ has joined #openstack-infra | 17:49 | |
| auristor | I've added some comments to the change in Gerrit | 17:49 |
| *** markvoelker has joined #openstack-infra | 17:51 | |
| *** mriedem_afk is now known as mriedem | 17:51 | |
| openstackgerrit | Clark Boylan proposed openstack/infra-manual master: Document why jobs queues are slow https://review.opendev.org/682098 | 17:51 |
| clarkb | corvus: ^ addressed your comments | 17:51 |
| clarkb | auristor: thank you | 17:51 |
| *** eharney has joined #openstack-infra | 17:51 | |
| clarkb | auristor: responded to your question there | 17:54 |
| openstackgerrit | David Shrewsbury proposed zuul/nodepool master: DNM: Demonstrate image leak https://review.opendev.org/682127 | 17:58 |
| openstackgerrit | David Shrewsbury proposed zuul/nodepool master: DNM: Demonstrate image leak https://review.opendev.org/682127 | 17:59 |
| Shrews | infra-root: I believe 682127 ^^^ will verify the bug that is causing the leaked images in vexxhost because of the leaked voluems. The fix is https://review.opendev.org/681857 but I wanted to see the test fail before including the fix. | 18:01 |
| Shrews | volumes | 18:02 |
| Shrews | i have no idea what a voluems is | 18:02 |
| *** panda has quit IRC | 18:02 | |
| *** panda has joined #openstack-infra | 18:03 | |
| fungi | i think it's french | 18:04 |
| clarkb | Shrews: neat bug | 18:05 |
| clarkb | that won't fix the volume leaks but will fix any image leaks unrelated to volume leaks? | 18:06 |
| clarkb | or at least give us the ability to delete the image once the volume is otherwise deleted | 18:06 |
| Shrews | clarkb: well, what I believe will happen is that we will now continue to retry deleting the image upload, but it will continue to fail until the leaked volume is removed | 18:07 |
| Shrews | so yah, your 2nd comment | 18:07 |
| Shrews | it's definitely related to volume leaks | 18:09 |
| Shrews | but i guess it could manifest in other ways (any error in deleting an upload) | 18:09 |
| Shrews | at least the fix is easy. the test was surprisingly difficult | 18:10 |
| *** nhicher has quit IRC | 18:15 | |
| *** nhicher has joined #openstack-infra | 18:15 | |
| openstackgerrit | Mohammed Naser proposed zuul/nodepool master: k8s: make context optional https://review.opendev.org/682130 | 18:17 |
| *** raschid has quit IRC | 18:26 | |
| *** jamesmcarthur has quit IRC | 18:26 | |
| openstackgerrit | Merged opendev/system-config master: Add docs for recovering an OpenAFS fileserver https://review.opendev.org/681338 | 18:27 |
| *** prometheanfire has quit IRC | 18:30 | |
| *** prometheanfire has joined #openstack-infra | 18:31 | |
| clarkb | corvus: if you have a sec to rereview https://review.opendev.org/#/c/682098/2 AJaeger has +2'd it. Then maybe we can send an email to the openstack-discuss list pointing people to that section | 18:32 |
| corvus | clarkb: +3 | 18:41 |
| clarkb | I've cleaned up the two nodes I held recently to debug job retries (one was for ironic and the other for octavia) | 18:42 |
| clarkb | guilhermesp: do you still need that held node? | 18:42 |
| openstackgerrit | Merged openstack/infra-manual master: Document why jobs queues are slow https://review.opendev.org/682098 | 18:45 |
| clarkb | corvus: thanks | 18:47 |
| AJaeger | published: https://docs.openstack.org/infra/manual/testing.html | 18:50 |
| clarkb | cool I'll send an email to openstack-discuss now with pointers to that | 18:51 |
| *** xek_ has joined #openstack-infra | 18:54 | |
| *** signed8bit has joined #openstack-infra | 18:55 | |
| *** lucasagomes has quit IRC | 18:59 | |
| *** goldyfruit___ has joined #openstack-infra | 18:59 | |
| *** goldyfruit_ has quit IRC | 19:02 | |
| *** markvoelker has quit IRC | 19:04 | |
| *** markvoelker has joined #openstack-infra | 19:06 | |
| mriedem | clarkb: https://review.opendev.org/#/c/682133/ should help with gate fail #2 | 19:11 |
| mriedem | http://status.openstack.org/elastic-recheck/#1813147 | 19:12 |
| mriedem | just fyi | 19:12 |
| clarkb | mriedem: are we reasnobly confident that enqueuing it without check results won't result in failures? | 19:12 |
| clarkb | eg you ran pep8 and pyxy unittests locally? | 19:12 |
| mriedem | pep8 yes and targeted unit and functional tests but not everything | 19:13 |
| mriedem | i can do that first | 19:13 |
| clarkb | cool let me know and I'll enqueue | 19:13 |
| clarkb | I smell lunch so I'll do that while I wait | 19:13 |
| *** lpetrut has joined #openstack-infra | 19:14 | |
| *** lpetrut has quit IRC | 19:15 | |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul master: DNM: show that mypy doesn't check type for caller https://review.opendev.org/682142 | 19:16 |
| *** lpetrut has joined #openstack-infra | 19:16 | |
| *** markvoelker has quit IRC | 19:16 | |
| *** markvoelker has joined #openstack-infra | 19:17 | |
| guilhermesp | sorry for the delay clarkb . I will need probably just for today | 19:20 |
| guilhermesp | if it is possible you schedule the clean up for tomorrow | 19:21 |
| clarkb | guilhermesp: no worries was just checking as I cleaned up my own holds | 19:21 |
| guilhermesp | it was good reminder btw, I did not touch it yesterday as I was planning so, gonna do today | 19:23 |
| *** kjackal has joined #openstack-infra | 19:27 | |
| mriedem | clarkb: yeah https://review.opendev.org/#/c/682133/ and https://review.opendev.org/#/c/682025/ are good for promotion, | 19:50 |
| mriedem | the former was promoted earlier today but failed due to the subunit parser bug | 19:50 |
| clarkb | ok I'll do that momentarily | 19:50 |
| mriedem | s/former/latter/ | 19:51 |
| clarkb | mriedem: whihc one happens more often (do you knwo?) I can put that one ahead of the other to slightly improve our chances | 19:51 |
| mriedem | subunit parser | 19:52 |
| mriedem | the former | 19:52 |
| *** slaweq has quit IRC | 19:52 | |
| mriedem | since your email i looked at http://status.openstack.org/elastic-recheck/#1686542 again and it looks like keystone and the openstack-tox-lower-constraints job there has the top hits | 19:53 |
| johnsom | Did something change in zuul that "zuul_work_dir" is no longer created automatically? | 19:53 |
| clarkb | ok https://review.opendev.org/#/c/682133/ first | 19:53 |
| clarkb | mriedem: ya keystone has had timeout issues in their tests cmorpheus has been working to bump the timeouts while the sort out the runtimes | 19:53 |
| fungi | johnsom: that sounds unlikely, but if you have an example failure maybe we can get to the bottom of it? | 19:53 |
| openstackgerrit | Fabien Boucher proposed zuul/zuul master: Pagure - add support for git.tag.creation event https://review.opendev.org/679938 | 19:54 |
| cmorpheus | the keystone timeouts have mostly gone away with the latest bump | 19:54 |
| johnsom | Here is the failure: https://zuul.opendev.org/t/openstack/build/9797918fd0e64899bfa6715b78179e5c/log/job-output.txt#464 | 19:54 |
| johnsom | Here is the zuul config: https://github.com/openstack/octavia/blob/master/zuul.d/jobs.yaml#L116 | 19:54 |
| cmorpheus | and we'll have a less bad fix once a few more changes get through | 19:54 |
| fungi | clarkb: mriedem: any idea if the ironic enospc aborts on rackspace are still ongoing? | 19:54 |
| clarkb | fungi: the change that dropped the disk sizes to 4GB merged | 19:54 |
| clarkb | fungi: at 1am pacific time today | 19:55 |
| fungi | ahh, okay, and any idea if that was sufficient to stem the failures? | 19:55 |
| mriedem | fungi: news to me | 19:55 |
| pabelanger | johnsom: octavia-lib is only pushed to disk | 19:55 |
| clarkb | I don't know how much that has helped their issues though it did seem to reduce the occurence of the issue on that particualr change as least | 19:55 |
| pabelanger | not octavia | 19:55 |
| openstackgerrit | Fabien Boucher proposed zuul/zuul master: Pagure - add support for git.tag.creation event https://review.opendev.org/679938 | 19:55 |
| clarkb | so with small data set it seemed to help but not fix? | 19:55 |
| johnsom | Right, octavia is not needed by the job | 19:55 |
| pabelanger | but zuul_work_dir is hardcoded to it? | 19:55 |
| pabelanger | can you drop that | 19:56 |
| clarkb | mriedem: I've enqueued both changes and there are no other nova changes ahead in the gate so I don't think we need to promote them | 19:56 |
| pabelanger | and use zuul.project.src_dir | 19:56 |
| fungi | mriedem: yeah, it wouldn't show up on e-r because the failure condition causes ansible to act like the network access died and so zuul retries the job. it can eventually result in retry_limit if the job gets unlucky and runs in the same provider thrice in a row | 19:56 |
| johnsom | I should say, it's not needed by the octavia-lib runs of that job | 19:56 |
| guilhermesp | all right clarkb you can clean the hold 23.253.245.79 :) | 19:57 |
| clarkb | guilhermesp: ok thanks | 19:57 |
| pabelanger | johnsom: I believe you can remove zuul_work_dir from your tox job, and should work as expected. Other wise octavia-tox-py37-tips expect to run against only octavia | 19:57 |
| johnsom | Hmm, ok, I will remove that and give it a try. It's just odd, as it was working ok. | 19:57 |
| johnsom | Maybe I can't share that definition between these two repos. | 19:58 |
| *** lpetrut has quit IRC | 19:58 | |
| fungi | johnsom: if octavia-lib changes had a depends-on declared to octavia changes i believe they'll end up with octavia checkouts there, could that be why it went unnoticed? | 19:59 |
| clarkb | cmorpheus: do keystones unittests run in parallel like nova and neutron? that is usually a major throughput bonus. If they do then great. Do you know why they are slow out of curiousity (eg disk io or network or cpu or ?) | 19:59 |
| johnsom | That could be actually. Most have been that way recently | 19:59 |
| johnsom | fungi for the win! | 19:59 |
| johnsom | lol | 19:59 |
| cmorpheus | clarkb: we think they are slow because we've been adding hundreds of unit tests | 19:59 |
| *** lucasagomes has joined #openstack-infra | 20:00 | |
| cmorpheus | clarkb: although sometimes they still run in <40 minutes and sometimes they take nearly 90 which i can only attribute to getting unlucky with node selection | 20:00 |
| cmorpheus | they do run in parallel i believe | 20:00 |
| clarkb | ya depending on what resources you need some clouds are defintiely slower than others | 20:00 |
| fungi | okay, i need to disappear to grab late lunch/early dinner while the tourists are otherwise occupied... i'll be back soon i hope | 20:01 |
| clarkb | johnsom: fyi we should have worlddump data for future failures with weird networking we can double check that to see if things are broken on the host https://review.opendev.org/#/c/680340/ | 20:01 |
| pabelanger | clarkb: it might be worth looking at hostid in inventory file, we recently seen a pattern of slow compute nodes in the clouds, which provider was able to fix. | 20:01 |
| cmorpheus | hmm we only have 'stestr run {posargs} and nothing about workers or paraellism in .stestr.conf | 20:01 |
| johnsom | clarkb Ok. Is fortnebula back in rotation? I haven't seen one of those failures recently | 20:02 |
| openstackgerrit | Fabien Boucher proposed zuul/zuul master: Pagure - handle Pull Request tags (labels) metadata https://review.opendev.org/681050 | 20:02 |
| clarkb | johnsom: I think at small scale. donnyd identified a retransmit problem with his router being overwhelmed and has redone the network architecture to put openstack router on dedicated instance | 20:02 |
| clarkb | johnsom: and monitoring shows retransmits have significantly fallen off | 20:03 |
| fungi | clarkb: johnsom: it's back up to 90 (assuming the change i approved eventially merged) | 20:03 |
| clarkb | donnyd: ^ you can probalby fill in johnsom better than I | 20:03 |
| clarkb | fungi: cool | 20:03 |
| johnsom | clarkb Ok cool. I will keep my eye out for runs. | 20:03 |
| fungi | yeah, says it merged at 17:16 | 20:03 |
| fungi | https://review.opendev.org/682107 | 20:03 |
| fungi | anyway, food. bbl | 20:04 |
| clarkb | cmorpheus: looks like they are in parallel. The little {X} prefix before your test names shows you which runner ran the test | 20:05 |
| cmorpheus | ah | 20:05 |
| *** panda has quit IRC | 20:05 | |
| clarkb | to compare to nova though: Ran: 17497 tests in 461.6404 sec. vs Ran: 7089 tests in 2283.5612 sec. | 20:07 |
| clarkb | there is a way to get a list of slow tests ( I'm surprised that stestr isn't showing that by default ) | 20:07 |
| * clarkb downloads the subunit file | 20:07 | |
| *** panda has joined #openstack-infra | 20:08 | |
| cmorpheus | we think the tests we added are inefficient because they use setUp() to recreate fixtures for each test, lbragstad was looking into optimizing it but hadn't been successful yet | 20:09 |
| donnyd | is there an issue with FN again | 20:09 |
| cmorpheus | https://review.opendev.org/663065 | 20:09 |
| *** igordc has joined #openstack-infra | 20:10 | |
| clarkb | donnyd: no, but johnsom had noticed dns issues on FN previously so was aksing if FN is back in the rotation now that we have extra debugging info | 20:10 |
| cmorpheus | splitting out those slow tests reduces the unit test time by more than half https://review.opendev.org/680788 | 20:10 |
| clarkb | donnyd: I think you tracked it to the likely culprit I was just pointing out we have extra info for debugging that in the future to rule in or out test host related issues | 20:10 |
| *** gfidente|afk has quit IRC | 20:11 | |
| donnyd | oh ok | 20:11 |
| johnsom | clarkb I found a grenade run at fortnebula that used IPv6 DNS successfully. So looking good so far. | 20:11 |
| clarkb | cmorpheus: https://gist.githubusercontent.com/cboylan/82f43a9c345100efcf155f82d936edf4/raw/9862d29614b9a541c35368971472f50e477d9782/keystone%2520unittest%2520runtimes I got that from this build https://zuul.opendev.org/t/openstack/build/05abcf573a4d402f9950176cd0fe813e | 20:13 |
| clarkb | cmorpheus: not sure if that helps | 20:13 |
| cmorpheus | clarkb: that confirms what we thought | 20:14 |
| cmorpheus | the keystone.tests.unit.protection.v3 are super slow | 20:15 |
| johnsom | clarkb Yeah, multiple good runs. This is likely fixed. | 20:15 |
| cmorpheus | and there are a crapton of them | 20:15 |
| AJaeger | config-core, a couple of changes that should be safe to merge: could you review https://review.opendev.org/681785 https://review.opendev.org/681276 https://review.opendev.org/#/c/681259/ https://review.opendev.org/681361 and https://review.opendev.org/680901 , please? | 20:15 |
| *** ykarel|away has quit IRC | 20:18 | |
| AJaeger | thanks, clarkb | 20:20 |
| clarkb | AJaeger: I'm about to head out for a short bike ride so not going to review (or approve) the zuul jobs change as that likly needs more attention (though if it is a new role should be safe) | 20:21 |
| AJaeger | clarkb: we have some more to review next week anyhow ;) Enjoy your ride! | 20:22 |
| * AJaeger wishes everybody a great weekend | 20:22 | |
| *** diablo_rojo__ has joined #openstack-infra | 20:23 | |
| *** diablo_rojo has quit IRC | 20:25 | |
| paladox | corvus fungi clarkb What do you think about https://imgur.com/MgF7zrp for the pg theme? | 20:26 |
| clarkb | paladox: pg is the js framework that newer gerrit uses? I think it looks fine. | 20:27 |
| paladox | yup | 20:28 |
| clarkb | cmorpheus: fwiw I used testr to get those numbers via test load < subnuit.file && testr slowest --all | 20:28 |
| clarkb | I have never really used stestr though I'm assuming it can do similar | 20:28 |
| clarkb | cmorpheus: that might be a good way to confirm you are making progress over time though | 20:28 |
| cmorpheus | clarkb: cool, good idea | 20:29 |
| openstackgerrit | Merged openstack/project-config master: Tighten formatting for new branch reno page title https://review.opendev.org/681785 | 20:30 |
| openstackgerrit | Merged openstack/project-config master: Report openstack/election repo changes in IRC https://review.opendev.org/681276 | 20:30 |
| openstackgerrit | Merged openstack/project-config master: End project gating for charm-neutron-api-genericswitch https://review.opendev.org/681259 | 20:30 |
| openstackgerrit | James E. Blair proposed zuul/zuul master: WIP: Support HTTP-only Gerrit https://review.opendev.org/681936 | 20:31 |
| openstackgerrit | Merged openstack/project-config master: Update horizon grafana dashboard https://review.opendev.org/681361 | 20:33 |
| corvus | paladox: :-D that looks great! | 20:33 |
| paladox | :) | 20:33 |
| paladox | i based it on our theme, but changed things so it incorporated opendev's logo. | 20:34 |
| paladox | (credits for our skin goes to Tyler Cipriani) | 20:34 |
| corvus | paladox: i love the nod to history here -- the gerrit theme was openstack+wikimedia infra teams' first collaboration | 20:35 |
| paladox | oh! | 20:35 |
| paladox | heh | 20:35 |
| openstackgerrit | Tristan Cacqueray proposed zuul/zuul master: Add tox-py37 to Zuul check https://review.opendev.org/682158 | 20:36 |
| paladox | I have the config to support gerrit 2.15-3.0 and the one for 3.1+ (https://gerrit-review.googlesource.com/c/gerrit/+/234734) | 20:36 |
| corvus | paladox: before our two projects got our hands on it, this is what gerrit looked like: https://www.researchgate.net/profile/Ahmed_E_Hassan/publication/266657830/figure/fig1/AS:357844848267264@1462328268100/An-example-Gerrit-code-review.png -- then openstack and wikimedia bounced some changes back and forth, and the result became the default theme for the remainder of the gwt era | 20:38 |
| paladox | corvus wow. | 20:39 |
| paladox | didn't know that :) | 20:39 |
| paladox | corvus https://phabricator.wikimedia.org/P9104 | 20:40 |
| paladox | that would be the config for you :) | 20:40 |
| paladox | that goes into gerrit-theme.html under static/ | 20:41 |
| *** whoami-rajat has quit IRC | 20:42 | |
| *** roman_g has quit IRC | 20:42 | |
| corvus | paladox: added to etherpad! | 20:42 |
| paladox | :) | 20:42 |
| paladox | corvus i have the gerrit 3.1 config too, just changing the things in it! :) | 20:42 |
| *** nhicher has quit IRC | 20:42 | |
| *** nhicher has joined #openstack-infra | 20:43 | |
| paladox | corvus https://phabricator.wikimedia.org/P9105 | 20:45 |
| paladox | very easy to define custom themes for users and allow them to enable it using localStorage! | 20:45 |
| paladox | *too | 20:45 |
| corvus | paladox: i'm looking forward to 'dark' myself :) | 20:49 |
| paladox | :P | 20:49 |
| corvus | clarkb, fungi: you know that thing where we comment out all the check jobs to work on something? i found a shorter version of that: rename the 'check' project-pipeline to experimental (assuming there isn't one already) then make a new check project-pipeline with the single job. | 20:50 |
| corvus | just a handy zuul tip | 20:50 |
| corvus | see https://review.opendev.org/#/c/681936/3/.zuul.yaml | 20:50 |
| *** openstackgerrit has quit IRC | 20:51 | |
| *** lbragstad has joined #openstack-infra | 20:51 | |
| mriedem | clarkb: in true karmic fashion, the subunit parser fix in the gate failed b/c of the other functional test gate bug | 20:51 |
| mriedem | which failed for reverse reasons earlier | 20:52 |
| corvus | mriedem: want to make an omnibus patch or re-promote? i can do the promote if you tell me what to do | 20:52 |
| mriedem | i'd prefer to not squash the fixes since i want to backport them as well | 20:53 |
| mriedem | corvus: does "promote" mean ninja merge? | 20:53 |
| mriedem | or just put it in the gate and skip check? | 20:53 |
| paladox | corvus i'm looking forward to a cleaner look & also zuul integration under gerrit.w.org | 20:53 |
| corvus | mriedem: put it top of gate and skip check | 20:53 |
| mriedem | corvus: does it need to finish it's run first? it's in the gate now | 20:53 |
| mriedem | https://review.opendev.org/#/c/682133/ i mean | 20:53 |
| corvus | mriedem: what's the other patch? | 20:54 |
| mriedem | corvus: https://review.opendev.org/#/c/682025/ | 20:56 |
| *** markvoelker has quit IRC | 20:57 | |
| corvus | mriedem: we can use promote to force a gate-reset and reconstruct it in the order we want. it's useful for flakey-test fixing patches because it lets us put the fixes at the top of the queue. but it always resets the entire queue, so if i used it right now, we would lose the work done on the current head (679510). if there's a chance that will merge (ie, we are not sure that it's just going to | 21:00 |
| corvus | hit a bug right at the end), then we should probably let it do so. let me give 3 options based on how you rate the urgency of these fixes: | 21:00 |
| corvus | mriedem: 1) most urgent: promote 682133 then 682025 immediately (will waste 679510 which will end up behind those). 2) somewhat urgent: wait 30m and promote 682133 and 682025 after 679510 finishes. 3) least urgent: dequeue 682133 and re-enqueue it at the back of the queue (least disruptive, but it'll be behind several other changes). | 21:02 |
| corvus | mriedem: (and, of course, we could do nothing. always an option :) | 21:02 |
| *** rh-jelabarre has quit IRC | 21:02 | |
| mriedem | #2 would be nice | 21:02 |
| mriedem | nova has 3 relatively beefy series approved since yesterday that we're trying to get through | 21:03 |
| mriedem | and given it's nova it takes awhile to get a node | 21:03 |
| *** pcaruana has quit IRC | 21:03 | |
| mriedem | so i'm cool with having that stuff maybe merged by sunday night, but it would suck to be middle of next week and we're still rechecking | 21:03 |
| corvus | k. i'll try to keep an eye out for 679510 clearing out and promote those 2 when it does | 21:04 |
| mriedem | great, thanks | 21:04 |
| corvus | mriedem: oh, one question is 682133 then 682025 the preferred order, or does it matter? | 21:04 |
| mriedem | yeah, based on e-r hits anyway | 21:04 |
| mriedem | but i'm not sure it matters too much since we've seen both fail today | 21:04 |
| corvus | cool. neutron just failed so i'm going it now. | 21:04 |
| mriedem | yeah that neutron patch failed hard https://storage.bhs1.cloud.ovh.net/v1/AUTH_dcaab5e32b234d56b626f72581e3644c/zuul_opendev_logs_54d/679510/1/gate/neutron-functional/54dc546/testr_results.html.gz | 21:05 |
| corvus | mriedem: done | 21:06 |
| corvus | hopefully we're luckier this time | 21:06 |
| mriedem | thanks again | 21:06 |
| corvus | np | 21:06 |
| paladox | corvus some of our users are waiting for 2.16 since it adds the project dashboard to PolyGerrit and also the inline editor! | 21:07 |
| corvus | paladox: i just used the inline editor a bit yesterday -- it's handy but takes getting used to (it's way to easy to forget to exit the editor -- and then after that you still have te remember to publish your drafts). that's something i heard folks talking about at the hackathon but didn't quite grasp at the time until i tried it and fell right into that trap. :) | 21:09 |
| paladox | heh | 21:09 |
| corvus | (basically i was like: "i got this. i totally know i need to publish my drafts before it's real" but then didn't realize i needed to stop editing before publishing) | 21:09 |
| paladox | yeh, though under PolyGerrit it saves anything you type to the local storage. | 21:09 |
| paladox | so that you can just load up the file and press save | 21:10 |
| paladox | there was a bug until earlier this year that made it impossible to use the inline editor. | 21:10 |
| paladox | that bug was a easy fix, but took sometime to find it :P | 21:10 |
| *** slaweq has joined #openstack-infra | 21:11 | |
| *** rf0lc0 has quit IRC | 21:12 | |
| *** slaweq has quit IRC | 21:16 | |
| clarkb | I use the inline editor to add depends on a lot | 21:19 |
| clarkb | particularly useful if I know i don't have a project cloned yet but am doing some testing of cross project stuff | 21:19 |
| *** KeithMnemonic has quit IRC | 21:19 | |
| *** diablo_rojo__ is now known as diablo_rojo | 21:20 | |
| clarkb | corvus: I did update https://review.opendev.org/#/c/682091/ with the lambda | 21:20 |
| *** kjackal has quit IRC | 21:28 | |
| *** lucasagomes has quit IRC | 21:30 | |
| *** openstackgerrit has joined #openstack-infra | 21:30 | |
| openstackgerrit | James E. Blair proposed zuul/zuul master: Support HTTP-only Gerrit https://review.opendev.org/681936 | 21:30 |
| *** efried is now known as efried_afk | 21:35 | |
| *** jbadiapa has quit IRC | 21:37 | |
| *** diablo_rojo has quit IRC | 21:44 | |
| *** xek_ has quit IRC | 21:46 | |
| *** xek has joined #openstack-infra | 21:47 | |
| *** xek has quit IRC | 21:49 | |
| *** xek has joined #openstack-infra | 21:49 | |
| *** mriedem has left #openstack-infra | 21:49 | |
| *** EvilienM is now known as EmilienM | 21:52 | |
| *** xek_ has joined #openstack-infra | 21:52 | |
| *** xek has quit IRC | 21:55 | |
| *** diablo_rojo has joined #openstack-infra | 21:59 | |
| *** munimeha1 has quit IRC | 22:03 | |
| *** mriedem has joined #openstack-infra | 22:04 | |
| *** markvoelker has joined #openstack-infra | 22:09 | |
| *** slaweq has joined #openstack-infra | 22:11 | |
| *** markvoelker has quit IRC | 22:14 | |
| *** slaweq has quit IRC | 22:16 | |
| openstackgerrit | Clark Boylan proposed openstack/project-config master: Rename x/ansible-role-cloud-launcher -> opendev/ https://review.opendev.org/662530 | 22:24 |
| clarkb | ok thats the rebsae to ensure the project rename changes are in the correct order | 22:24 |
| clarkb | ok there is a bug in our gitea-rename-tasks.yaml playbook. It uses an ansible playbook/tasks list that no longer exists in order to create the orgs | 22:28 |
| clarkb | because we don't create any new orgs in this rename I think that is ok | 22:28 |
| clarkb | https://opendev.org/opendev/system-config/src/branch/master/playbooks/gitea-rename-tasks.yaml#L24-L27 we can delete that task when we run it on monday but that should be fixed | 22:29 |
| *** mriedem is now known as mriedem_afk | 22:30 | |
| clarkb | corvus: for https://opendev.org/opendev/system-config/src/branch/master/playbooks/gitea-rename-tasks.yaml#L28-L68 that section should be fine since it reimplements what was in the old task lists anyway right? basically the libification of these http requests didn't change behavior it just turned it into python to avoid the process exec cost | 22:30 |
| *** rlandy has quit IRC | 22:38 | |
| *** Goneri has quit IRC | 22:41 | |
| *** pkopec has quit IRC | 22:46 | |
| *** goldyfruit___ has quit IRC | 22:49 | |
| corvus | clarkb: that is a task list? | 22:55 |
| corvus | we moved some project creation stuff to a module | 22:56 |
| corvus | but that shouldn't have a bearing here? | 22:56 |
| clarkb | well https://opendev.org/opendev/system-config/src/branch/master/playbooks/gitea-rename-tasks.yaml#L24-L27 imports a file that was deleted in that module move. But we don't need that bit. The other question was whether or not we added anything to the code that moved into python code | 22:56 |
| clarkb | I don't think we did so the ansible http tasks we use to rename should be fine (just slower than the python we could rewrite them in) | 22:57 |
| *** xek_ has quit IRC | 22:59 | |
| *** mattw4 has quit IRC | 23:11 | |
| *** diablo_rojo has quit IRC | 23:12 | |
| *** tosky has quit IRC | 23:23 | |
| *** xenos76 has quit IRC | 23:25 | |
| fungi | corvus: woah, mind blown. s/check/experimental/ is an awesome trick i would never have thought of | 23:26 |
| fungi | paladox: that theme looks nice and clean to me, though it seems like the change view and diff view pages are usually where gerrit theming really gets hairy | 23:31 |
| *** gyee has quit IRC | 23:32 | |
| paladox | fungi looks like this https://imgur.com/a/ImGOuMe on the diff view | 23:32 |
| *** gyee has joined #openstack-infra | 23:35 | |
| fungi | ahh, yeah that looks pretty good too | 23:40 |
| *** gyee has quit IRC | 23:51 | |
| *** rcernin has joined #openstack-infra | 23:56 | |
Generated by irclog2html.py 2.15.3 by Marius Gedminas - find it at mg.pov.lt!
{kind=link}
{kind=link}
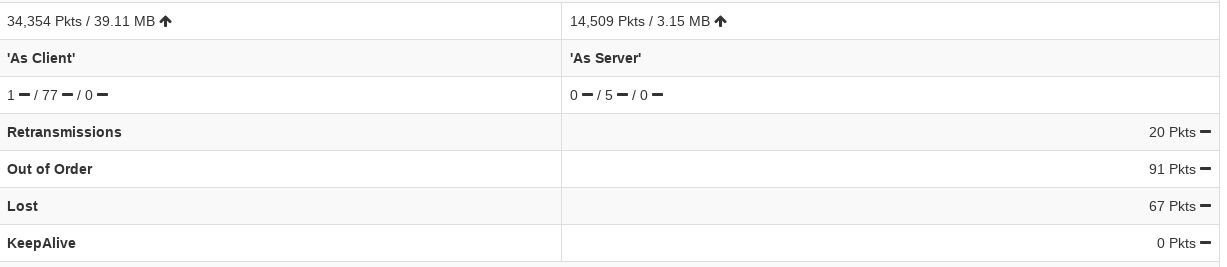{kind=link}
{kind=link}